This blog is dedicated to improving the quality of Second Language Teacher Education (SLTE)
The Teacher Trainers and Educators
The most influential ELT teacher trainers and educators are those who publish “How to teach” books and articles, have on-line blogs and a big presence on social media, give presentations at ELT conferences, and travel around the world giving workshops and teacher training & development courses. Many of the best known and highest paid teacher educators are also the authors of coursebooks. Apart from the top “influencers”, there are tens of thousands of teacher trainers worldwide who deliver pre-service courses such as CELTA, or the Trinity Cert TESOL, or an MA in TESOL, and thousands working with practicing teachers in courses such as DELTA and MA programmes. Special Interest Groups in TESOL and IATEFL also have considerable influence.
What’s the problem?
Most current SLTE pays too little attention to the question “What are we doing?”, and the follow-up question “Is what we’re doing effective?”. The assumption that students will learn what they’re taught is left unchallenged, and those delivering SLTE concentrate either on coping with the trials and tribulations of being a language teacher (keeping fresh, avoiding burn-out, growing professionally and personally) or on improving classroom practice. As to the latter, they look at new ways to present grammar structures and vocabulary, better ways to check comprehension of what’s been presented, more imaginative ways to use the whiteboard to summarise it, more engaging activities to practice it, and the use of technology to enhance it all, or do it online. A good example of this is Adrian Underhill and Jim Scrivener’s “Demand High” project, which leaves unquestioned the well-established framework for ELT and concentrates on doing the same things better. In all this, those responsible for SLTE simply assume that current ELT practice efficiently facilitates language learning. But does it? Does the present model of ELT actually deliver the goods, and is making small, incremental changes to it the best way to bring about improvements? To put it another way, is current ELT practice efficacious, and is current SLTE leading to significant improvement? Are teachers making the most effective use of their time? Are they maximising their students’ chances of reaching their goals?
As Bill VanPatten argues in his plenary at the BAAL 2018 conference, language teaching can only be effective if it comes from an understanding of how people learn languages. In 1967, Pit Corder was the first to suggest that the only way to make progress in language teaching is to start from knowledge about how people actually learn languages. Then, in 1972, Larry Selinker suggested that instruction on formal properties of language has a negligible impact (if any) on real development in the learner. Next, in 1983, Mike Long raised the issue again of whether instruction on formal properties of language made a difference in acquisition. Since these important publications, hundreds of empirical studies have been published on everything from the effects of instruction to the effects of error correction and feedback. This research in turn has resulted in meta-analyses and overviews that can be used to measure the impact of instruction on SLA. All the research indicates that the current, deeply entrenched approach to ELT, where most classroom time is dedicated to explicit instruction, vastly over-estimates the efficacy of such instruction.
So in order to answer the question “Is what we’re doing effective?”, we need to periodically re-visit questions about how people learn languages. Most teachers are aware that we learn our first language/s unconsciously and that explicit learning about the language plays a minor role, but they don’t know much about how people learn an L2. In particular, few teachers know that the consensus of opinion among SLA scholars is that implicit learning through using the target language for relevant, communicative purposes is far more important than explicit instruction about the language. Here are just 4 examples from the literature:
1. Doughty, (2003) concludes her chapter on instructed SLA by saying:
In sum, the findings of a pervasive implicit mode of learning, and the limited role of explicit learning in improving performance in complex control tasks, point to a default mode for SLA that is fundamentally implicit, and to the need to avoid declarative knowledge when designing L2 pedagogical procedures.
2. Nick Ellis (2005) says:
the bulk of language acquisition is implicit learning from usage. Most knowledge is tacit knowledge; most learning is implicit; the vast majority of our cognitive processing is unconscious.
3. Whong, Gil and Marsden’s (2014) review of a wide body of studies in SLA concludes:
“Implicit learning is more basic and more important than explicit learning, and superior. Access to implicit knowledge is automatic and fast, and is what underlies listening comprehension, spontaneous speech, and fluency. It is the result of deeper processing and is more durable as a result, and it obviates the need for explicit knowledge, freeing up attentional resources for a speaker to focus on message content”.
4. ZhaoHong, H. and Nassaji, H. (2018) review 35 years of instructed SLA research, and, citing the latest meta-analysis, they say:
On the relative effectiveness of explicit vs. implicit instruction, Kang et al. reported no significant difference in short-term effects but a significant difference in longer-term effects with implicit instruction outperforming explicit instruction.
Despite lots of other disagreements among themselves, the vast majority of SLA scholars agree on this crucial matter. The evidence from research into instructed SLA gives massive support to the claim that concentrating on activities which help implicit knowledge (by developing the learners’ ability to make meaning in the L2, through exposure to comprehensible input, participation in discourse, and implicit or explicit feedback) leads to far greater gains in interlanguage development than concentrating on the presentation and practice of pre-selected bits and pieces of language.
One of the reasons why so many teachers are unaware of the crucial importance of implicit learning is that so few of those responsible for SLTE talk about it. Teacher trainers and educators don’t tell pre-service or practicing teachers about the research findings on interlanguage development, or that language learning is not a matter of assimilating knowledge bit by bit; or that the characteristics of working memory constrain rote learning; or that by varying different factors in tasks we can significantly affect the outcomes. And there’s a great deal more we know about language learning that those responsible for SLTE don’t pass on to teachers, even though it has important implications for everything in ELT from syllabus design to the use of the whiteboard; from methodological principles to the use of IT, from materials design to assessment.
We know that in the not so distant past, generations of school children learnt foreign languages for 7 or 8 years, and the vast majority of them left school without the ability to maintain an elementary conversational exchange in the L2. Only to the extent that teachers have been informed about, and encouraged to critically evaluate, what we know about language learning, constantly experimenting with different ways of engaging their students in communicative activities, have things improved. To the extent that teachers continue to spend most of the time talking to their students about the language, those improvements have been minimal. So why is all this knowledge not properly disseminated?
Most teacher trainers and educators, including Penny Ur (see below), say that, whatever its faults, coursebook-driven ELT is practical, and that alternatives such as TBLT are not. Ur actually goes as far as to say that there’s no research evidence to support the view that TBLT is a viable alternative to coursebooks. Such an assertion is contradicted by the evidence. In a recent statistical meta-analysis by Bryfonski & McKay (2017) of 52 evaluations of program-level implementations of TBLT in real classroom settings, “results revealed an overall positive and strong effect (d = 0.93) for TBLT implementation on a variety of learning outcomes” in a variety of settings, including parts of the Middle-East and East Asia, where many have flatly stated that TBLT could never work for “cultural” reasons, and “three-hours-a-week” primary and secondary foreign language settings, where the same opinion is widely voiced. So there are alternatives to the coursebook approach, but teacher trainers too often dismiss them out of hand, or simply ignore them.
How many SLTE courses today include a sizeable component devoted to the subject of language learning, where different theories are properly discussed so as to reveal the methodological principles that inform teaching practice? Or, more bluntly: how many such courses give serious attention to examining the complex nature of language learning, which is likely to lead teachers to seriously question the efficacy of basing teaching on the presentation and practice of a succession of bits of language? Current SLTE doesn’t encourage teachers to take a critical view of what they’re doing, or to base their teaching on what we know about how people learn an L2. Too many teacher trainers and educators base their approach to ELT on personal experience, and on the prevalent “received wisdom” about what and how to teach. For thirty years now, ELT orthodoxy has required teachers to use a coursebook to guide students through a “General English” course which implements a grammar-based, synthetic syllabus through a PPP methodology. During these courses, a great deal of time is taken up by the teacher talking about the language, and much of the rest of the time is devoted to activities which are supposed to develop “the 4 skills”, often in isolation. There is good reason to think that this is a hopelessly inefficient way to teach English as an L2, and yet, it goes virtually unchallenged.
Complacency
The published work of most of the influential teacher educators demonstrates a poor grasp of what’s involved in language learning, and little appetite to discuss it. Penny Ur is a good example. In her books on how to teach English as an L2, Ur spends very little time discussing the question of how people learn an L2, or encouraging teachers to critically evaluate the theoretical assumptions which underpin her practical teaching tips. The latest edition of Ur’s widely recommended A Course in Language Teaching includes a new sub-section where precisely half a page is devoted to theories of SLA. For the rest of the 300 pages, Ur expects readers to take her word for it when she says, as if she knew, that the findings of applied linguistics research have very limited relevance to teachers’ jobs. Nowhere in any of her books, articles or presentations does Ur attempt to seriously describe and evaluate evidence and arguments from academics whose work challenges her approach, and nowhere does she encourage teachers to do so. How can we expect teachers to be well-informed, critically acute professionals in the world of education if their training is restricted to instruction in classroom skills, and their on-going professional development gives them no opportunities to consider theories of language, theories of language learning, and theories of teaching and education? Teaching English as an L2 is more art than science; there’s no “best way”, no “magic bullet”, no “one size fits all”. But while there’s still so much more to discover, we now know enough about the psychological process of language learning to know that some types of teaching are very unlikely to help, and that other types are more likely to do so. Teacher educators have a duty to know about this stuff and to discuss it with thier trainees.
Scholarly Criticism? Where?
Reading the published work of leading teacher educators in ELT is a depressing affair; few texts used for the purpose of teacher education in school or adult education demonstrate such poor scholarship as that found in Harmer’s The Practice of Language Teaching, Ur’s A Course in Language Teaching, or Dellar and Walkley’s Teaching Lexically, for example. Why are these books so widely recommended? Where is the critical evaluation of them? Why does nobody complain about the poor argumentation and the lack of attention to research findings which affect ELT? Alas, these books typify the general “practical” nature of SLTE, and their reluctance to engage in any kind of critical reflection on theory and practice. Go through the recommended reading for most SLTE courses and you’ll find few texts informed by scholarly criticism. Look at the content of SLTE courses and you’ll be hard pushed to find a course which includes a component devoted to a critical evaluation of research findings on language learning and ELT classroom practice.
There is a general “craft” culture in ELT which rather frowns on scholarship and seeks to promote the view that teachers have little to learn from academics. Those who deliver SLTE are, in my opinion, partly responsible for this culture. While it’s unreasonable to expect all teachers to be well informed about research findings regarding language learning, syllabus design, assessment, and so on, it is surely entirely reasonable to expect teacher trainers and educators to be so. I suggest that teacher educators have a duty to lead discussions, informed by relevant scholarly texts, which question common sense assumptions about the English language, how people learn languages, how languages are taught, and the aims of education. Furthermore, they should do far more to encourage their trainees to constantly challenge received opinion and orthodox ELT practices. This surely, is the best way to help teachers enjoy their jobs, be more effective, and identify the weaknesses of current ELT practice.
My intention in this blog is to point out the weaknesses I see in the works of some influential ELT teacher trainers and educators, and invite them to respond. They may, of course, respond anywhere they like, in any way they like, but the easier it is for all of us to read what they say and join in the conversation, the better. I hope this will raise awareness of the huge problem currently facing ELT: it is in the hands of those who have more interest in the commercialisation and commodification of education than in improving the real efficacy of ELT. Teacher trainers and educators do little to halt this slide, or to defend the core principles of liberal education which Long so succinctly discusses in Chapter 4 of his book SLA and Task-Based Language Teaching.
The Questions
I invite teacher trainers and educators to answer the following questions:
1 What is your view of the English language? How do you transmit this view to teachers?
2 How do you think people learn an L2? How do you explain language learning to teachers?
3 What types of syllabus do you discuss with teachers? Which type do you recommend to them?
4 What materials do you recommend?
5 What methodological principles do you discuss with teachers? Which do you recommend to them?
References
Bryfonski, L., & McKay, T. H. (2017). TBLT implementation and evaluation: A meta-analysis. Language Teaching Research.
Dellar, H. and Walkley, A. (2016) Teaching Lexically. Delata.
Doughty, C. (2003) Instructed SLA. In Doughty, C. & Long, M. Handbook of SLA, pp 256 – 310. New York, Blackwell.
Long, M. (2015) Second Language Acquisition and Task-Based Language Teaching. Oxford, Wiley.
Ur, P. A Course in Language Teaching. Cambridge, CUP.
Whong, M., Gil, K.H. and Marsden, H., (2014). Beyond paradigm: The ‘what’ and the ‘how’ of classroom research. Second Language Research, 30(4), pp.551-568.
ZhaoHong, H. and Nassaji, H. (2018) Introduction: A snapshot of thirty-five years of instructed second language acquisition. Language Teaching Research, in press.
Currently, Marek Kiczkowiak runs TEFL Equity Advocates, the TEFL Equity Academy and Academic English Now, but there are hints of even greater ventures in the pipeline. In a recent video (3 Lessons From Making $70k A Month Teaching English Online), Kiczkowiak boasts of making $70,000 a month from Academic English Now, and announces that he’s ready to share the secrets of his success with teachers everywhere so that they can “start and grow a wildly profitable ELT business that makes you at least $30,000 a month”. (Just by the way, I urge you to watch the “3 lessons” video. It’s a masterclass in slick promotion and the expertese on show contrasts dramatically with the quality of Kiczkowiak’s academic work.) Well, if he himself can make $70,000 a month income, doesn’t that show he’s the man to help EFL teachers make $30,000 a month? Well of course it does. Just phone him for a friendly chat and sign the contract; it’s as simple as that.
Or is it? There are, I think, a few doubts about this rapidly-expanding business endeavour, fuelled by Kiczkowiak’s “one trick pony” academic credentials and his business practices.
History
Kiczkowiak became well-known in ELT circles in 2016 when he gave a presentation at the IATEFL conference calling out employers who used a “Native Speakers Only” policy. He set up a web site called TEFL Equity Advocates to fight the cause of NNESTs, which quickly gained a large following. By the end of the year, promotional material for training courses at his TEFL Equity Academy were being displayed on the front page of his TEFL Equity Advocates web site. I pointed out this conflict of interests on my blog, arguing that Kiczkowiak had developed a powerful brand to promote the cause of fighting discrimination against NNESTs and subsequently used that brand name to promote his own private commercial interests. Kiczkowiak hotly denied the “accusations”, but as Russell Crew-Gee pointed out in the “Comments” section, “the Equity Academy is clearly present as a link on the front page of the TEFL Equity Advocates web page. Hence, Geoff’s premise that the Academy is being promoted directly by the Equity Advocacy website is undeniable, a Factual Reality”.
After making a few changes to his website, Kiczkowiak continued to use the TEFL Equity Advocates brand to promote his own commercial, teacher training courses. I reckon that the goodwill created by the TEFL Equity Advocacy activities definitely benefited Kiczkowiak’s private commercial interests, and his inability to accept this fact makes me question his business ethics.
Metamorphosis
From 2016 on, Kiczkowiak continued to champion both his cause and his courses, but he also did a PhD and published articles in an assortment of journals. Soon, a new persona emerged: Marek Kiczkowiak, the Widely-Puublished-Whiz-Kid-Academic, ready and able to help aspiring academics write dazzling PhD theses and academic articles in not much more time than it takes to transfer a few thousand dollars from your account to his.
Apart from his PhD (two a penny these days, eh?), what are Kiczkowiak’s credentials? I looked on Google Scholar and found these (the 2 columns on the right give citations and year of publication):
I’ve rarely seen a list that more strongly indicates a “one trick pony”, a term used in academia to describe a member of staff with an unacceptably narrow range. These days, nobody expects any Leornado de Vinci-like polymaths to fight for one of the diminishing number of tenured postions available in university departments, but nevertheless, there are quite high standards to meet, and Kiczkowiak’s publications just don’t meet them. The one topic he writes about is not just extremely limited, it’s contentious. ”Native speakerism” is the overtly political, obscurantist construct of A. Holliday, a blustering scholar who talks nonsense with all the conviction of a relgious zealot.
A further doubt about Dr. Kiczkowiak arises from an inspection of where his articles were published. IATEFL Voices, University of York, Teacher Education and Development Journal, British Council Voices Magazine, TESL-EJ, and a short entry to an encyclopedia are hardly the journals where all the best academics seek to get published.
Then there’s the content. Native-speakerism and the complexity of personal experience: A duoethnographic study by RJ Lowe and M Kiczkowiak, consists of conversations between the two authors about being native or non-native speaker teachers of English – Lowe’s the NEST and Kiczkowiak is the NNEST. Data from the duoethnographic study (or “chats” as they’re called in plain English) indicate “that the effects of native-speakerism can vary greatly from person to person based on not only their “native” or “non-native” positioning, but also on geography, teaching context and personal disposition”. Who knew!
The article begins:
“Native-speakerism is a term coined and described by Holliday (2003, 2005, 2006), which is used to refer to a widespread ideology in the English Language Teaching (ELT) profession whereby those perceived as “native speakers” of English are considered to be better language models and to embody a superior Western teaching methodology than those perceived as “non-native speakers”. This ideology makes extensive use of an “us” and “them” dichotomy where “non-native speaker” teachers and students are seen as culturally inferior and in need of training in the “correct” Western methods of learning and teaching. Native-speakerism also makes extensive use of what Holliday (2005) calls “cultural disbelief” (see also Holliday, 2013, 2015); a fundamental doubt that “non-native speakers” can make any meaningful contributions to ELT.
Holliday’s initial description of native-speakerism as an ideology that benefits “native speakers” to the detriment of “non-native speakers” has been recently criticised by Houghton and Rivers, who, in their edited volume (Houghton & Rivers (2013) show that “native speakers” can also be affected negatively by the ideology. Consequently, native-speakerism can now be understood as an ideology which, while privileging the knowledge and voices of Western ELT institutions, uses biases and stereotypes to classify people (typically language teachers) as superior or inferior based on their perceived belonging or lack of belonging to the “native speaker” group (Holliday, 2015); Houghton & Rivers, 2013)”.
Now let’s see how the article Confronting Native Speakerism …, written a year later, begins:
“‘Native speakerism’ is a term coined by Holliday (2005, 2006) by which he referred to the belief that the ideals of English Language Teaching (ELT) methodology and practice originate in Western culture, which in turn is embodied by a ‘native speaker’ of English, who is deemed the ideal teacher. Houghton and Rivers (2013, p. 14) reconceptualise this definition to show that both ‘native’ and ‘non-native speakers’ can be negatively impacted by native-speakerism, which is now understood as: a prejudice, stereotyping and/or discrimination, typically by or against foreign language teachers, on the basis of either being or not being perceived and categorized as a native speaker of a particular language. (…) Its endorsement positions individuals from certain language groups as being innately superior to individuals of other language groups”. Do you spot any similarities?
Next, the “article” Teaching English as a lingua franca: The journey from EFL to ELF . Oh, it’s not actually an article published in an academic journal, it’s an extract from a book.
Seven principles for writing materials for English as a lingua franca is a short piece for the ELTJ which gives advice to materials writers such as “use authentic E(LF)nglish rather than ‘native speaker’ corpora” and “use Multilingual E(LF) rather than monolingual ‘native speaker’ language”. The claim is that these “principles” should help to cancel the contribution current coursebooks make to “the entrenchment of what Holliday (2005) has referred to as the ideology of native speakerism”.
Using awareness raising activities on initial teacher training courses to tackle ‘native-speakerism’ begins “Native Speakerism is a term coined by Holliday (2005, 2006) which refers to the belief that the Native English Speaker (NES) is the embodiment of the values and ideals of English Language Teaching (ELT) pedagogy and knowledge”.
Recruiters’ Attitudes to Hiring ‘Native’ and ‘Non-Native Speaker’ Teachers: An International Survey is the only article that has merit, in my opinion. The survey is competently designed and implemented and its findings are clearly and honestly set out.
You’ll have to take my word for it when I say that the rest of the articles are further variations on the same theme, and allow me to deal with just one more: the 2021 article by Kiczkowiak and Lowe, “Native-speakerism in English language teaching: ‘Native speakers’ more likely to be invited as conference plenary speakers”. This is one of the very few Kiczkowiak texts that actually discusses what the terms “native speaker” and “non-native speaker” refer to. The authors begin by explaining why they diasagree with the concepts of ‘native speaker’ and ‘non-native speaker’. These terms have been used in SLA research as “neutral scientific labels” primarily based on early exposure to the language, but Kiczkowiak and Lowe prefer to see them as “social and political constructs”, which “arose in the context of city states attempting to consolidate their power and develop ideas of shared identity among the citizenry (Hackert 2012; Train 2009)”.
The authors then settle into their favorite territory: Holliday land. Any use of the terms NS and NNS labels is “ideological, chauvinistic and divisive” and the continuous use of the labels “routinises and normalises them (Holliday 2013, 2018)”. The authors go on to explain that, despite their enthusiastic endorsement of Holliday’s views, they feel forced to use the terms native speaker and non-native speaker in their analysis, but to partially cover their embarrassment, they follow Holliday (2005) by placing the terms in inverted commas to remind themselves and their readers “of their ideological and subjective nature”. Having apologised for the brevity of their review, the authors move to a report of their study, which found that “out of a total of 416 plenaries, only 25 per cent were given by ‘non-native speakers’ and 0.06 per cent by speakers of colour”.
The discussion of “native speakerism” in the article is entirely inadequate and the poor standard of academic discussion evdent here extends to, indeed pervades, all of Kiczkowiak’s articles. In this article, as in so many others, the authors simply assert this that and the other about the terms native speaker and non-native speaker and the construct of native speakerism without going to the trouble of describing or engaging in any critical evaluation of other views. Below is a quick sketch of one such view.
Native speakerness is a psychological reality.
In the domain of SLA research, native speakers of language X are people for whom language X is the language they learnt through primary socialization in early childhood, as a first language. To paraphrase Long (2007, 2015), the psychological reality of native speakerness is easily demonstrated by the fact that we know one, and who isn’t one, when we meet them, often on the basis of just a few utterances. When English native speakers are presented with recorded stretches of speech by a large pool of NSs and NNSs and asked to say which are which, they distinguish between them with reliability typically well above .9. How do they do this, and why is there so much agreement if, according to Holliday, there’s no such thing as a NS?
For the last 70 years, the term “native speaker” has been used in SLA studies to investigate the failure of the vast majority of post adolescent L2 learners to achieve what Birdsong refers to as “native like attainment”. “On the prevailing view of ultimate attainment in second language acquisition, with few exceptions, native competence cannot be achieved by post pubertal learners “(Birdsong 1992).
The specific claim that very few post adolescent L2 learners attain native like proficiency is supported by a great deal of empirical evidence (see, e.g., reviews by Long 2007, Harley and Wang 1995; Hyltenstam and Abrahamsson 2003). When trying to explain why most L2 learners don’t attain native competence, scholars have investigated various “sensitive periods”. Long (2007) argues that the issue of age differences is fundamental for SLA theory construction. If the evidence from sensitive periods shows that adults are inferior learners because they are qualitatively different from children, then this could provide an explanation for the failure of the vast majority of post adolescent L2 learners to achieve Birdsong’s “native like attainment”. On the other hand, if we want to propose the same theory for child and adult language acquisition, then we’ll have to account for the differences in outcome some other way; for example, by claiming that the same knowledge and abilities produce inferior results due to different initial states in L1 acquisition and L2 acquisition. Either way, the importance of the existence (or not) of sensitive periods for those scholars trying to explain the psychological process of SLA suggests the usefulness of using the native speaker as a measure of the proficiency of adult L2 learners.
Most importantly, using the NS and NNS terms does not, pace Kiczkowiak, entail assuming that native speakers of English are better language models or better teachers than non-native speakers.
Assertions don’t make an argument
Kiczkowiak cites the work of scholars who argue against the view outlined above, including some, like Vivian Cook, who do it very persuasively. The trouble is that Kiczkowiak doesn’t bother to lay out the argument made by these scholars; he simply states their assertions as if their persuasiveness spoke for itself. In the Kiczkowiak and Lowe (2021) article, work by Dewaele, Bak, and Ortega (2021); Hackert (2012); Train (2009); Aboshiha (2015); Amin (1997); Kubota and Fujimoto (2013) Ruecker and Ives (2015); Rampton (1990); Paikeday (1985); Cook (2001); Jenkins (2015); Dewaele (2018); and others are cited, but no attempt is made to present or critically discuss their views. Thus Kiczkowiak makes the elementary mistake made by inexperienced postgrad students: he cites scholars’ assertions as if doing so automatically lends support to his own argument. In any case, the paper, like all the others, is hampered by having to start from Holliday’s assumption that the key terms under discussion don’t actually exist.
Holliday’s “racist native speakerism” and “essentialism”
The most frequently cited source in all Kiczkowiak’s articles about native speakerism is, of course Holliday. As we’ve seen, Kiczkowiak begins quite a few of his articles by giving a summary of Holliday’s construct of native speakerism, a construct which Kiczkowiak never attempts to evaluate, presumeably because he’s so thoroughly convinced of its truth, including Holliday’s assertion that using the acronyms NS and NNS is clear evidence of racism.
In a post on his blog, Holliday says that “In academia the established use of ‘native speaker’ as a sociolinguistic category comes from particular paradigmatic discourses of science and is not fixed beyond critical scrutiny”. This is the kind of bunkum that so often goes unchalleged these days and bad scholars like Kiczkowiak actually emulate such incoherent claims. What does the phrase “particular paradigmatic discourses of science” refer to? Scientific method, that’s what. Holliday asserts that adopting a realist epistemology, and carrying out quantitative research by testing well-articulated hypotheses with empirical evidence and logical argument is part of a “mistaken paradigm”. When one compares the results of adopting this paradigm (visit the Science Museum in South Kensington or browse their website) with the results of adopting Holliday’s approach to research (I don’t know of any important results), one quickly appreciates the proposterousness of that claim. Anyway, since in the field of SLA research there isn’t – and never has been – any general theory of SLA with paradigm status, talk of paradigms (like talk of “imagined objective ‘science’” and labels placed in inverted commas that refer to things that “do not actually exist at all”) belongs only to the topsy-turvy world of post-modern sociology.
Holliday asserts that when we refer to people as ‘non-native speakers’, we imply that they are “culturally deficient”, and that this amounts to “deep and unrecognised racism”. Referring to people as non-native speakers “defines, confines and reduces” them by referring to their culture in a way that evokes “images of deficiency or superiority – divisive associations with competence, knowledge and race – who can, who can’t, and what sort of people they are”. These sweeping assertions are “supported” by Holliday’s construct of essentialism. At a minor conference held somewhere in England in 2019, Holliday explained:
Essentialism is to do with ‘Us-Them’ discourse. ‘They’ are essentially different to ‘Us’ because of their culture…… There’s no way we can be the same. There’s something absolutely separate about us and them. ……. Culture then becomes a euphemism for race. It’s essentially racist to imagine a group here and a group there who are essentially different to each other. That is the root of racism…….. Any group who is put over there and defined as being different to you, that is the basis of racism. …………… Grand narratives define “us” and “them” by fixity and division. We are different to those people, we have to be in order to survive. .. You brand your nation as being different to those people, in a superior or inferior way.
As evidence for his thesis, Holliday gives the example of a Chinese student who told him he’d turned down a fantastic job in Mexico “because Mexico is not as good as Britain”. Holliday explains: He had a hierarchy in his head. I challenge everybody in this room …. We all position ourselves …There’s no such thing as talking about culture in a neutral way; we just cannot. Everybody is positioning themselves in a hierarchy.
In another meaning-drenched anecdote, Holliday recalls the time he was in Istanbul interviewing colleagues. “We were sitting right on the Bosphorus. And everything that was East was inferior, and everything that was West was superior. This came out, very very clear; very very clear. Even inside Turkey”. The obvious question to ask is: How does Holliday know all this stuff about what people are thinking? How did he know that his Chinese student had a hierarchy in his head, or that his companions in Istanbul made the “essentialist statement” that “‘They’ are essentially different to ‘Us’”? Why should we believe for a second that Holliday has somehow correctly read people’s minds?
Lets suppose we ask a group of scientists, born and raised in France, who all adopt a realist epistemology and carry out quantitative research, to watch a documentary about life in Beijing where the locals are shown working and playing and doing the everyday things they do. Regardless of what they might say, Holliday will insist that the scientists’ “positivist ideology” will make them all think, consciously or not: “Those people are essentially different to us. There’s no way we can be the same. There’s something absolutely separate about us and them”. Holliday will also insist that they’re all racists. If the scientists deny these charges, Holliday will take the approved line of the critical social justice brigade and say they’re blind to their racism. They can’t help themselves: they can’t escape their cultural influences and the consequences of their “positivist ideology”.
In short, “postivists” are bad people. The good people are epistemological relativists like Holliday, those who rely on the interpretation of subjective experiences and who reject the scientific, “positivist paradigm”. To be clear: Holliday’s commitment to a qualitative, ethnographic methodology and to a constructivist, relativist epistemology amounts to abandoning reason. Having done so, Holliday is free to harangue people in his zealous pursuit of racists and all the other bad people whose ideologies he finds so offensive. Holliday limits the scope of his descriptions to a single, preferred interpretation which is not just partial, but also ideologically blinkered. It’s scary.
Kiczkowiak The Scholar
Kiczkowiak leans on Holliday. Holliday’s views provide the theoretical underpinning for Kiczkowiak’s rants against “native speakerism”. Search Kiczkowiak’s narrow little oevre and you’ll find no trace of originality, or valuable insights, or critical acumen, or any appreciation for what academic work is really about. When attempting to deal with other scholar’s work, Kiczkowiak conflates the work of scholars who have little in common, failing to acknowledge the very different views of V. Cook , Holliday and Widdowson, for example, or the important differences between the group that comprises critical applied linguists, including Phillipson, Pennycock, Canagarajah, and Edge. More generally he fails to differentiate between those academics who oppose discrimination against NNESTs (just about everybody) and those who belong to the critical social justice movement, whose views Kiczkowiak manages to simultaneously applaud and misrepresent. In short, Kiczkowiak’s oeuvre gives scant cause for trusting his judgements or advice on writing academic texts.
Current Situation
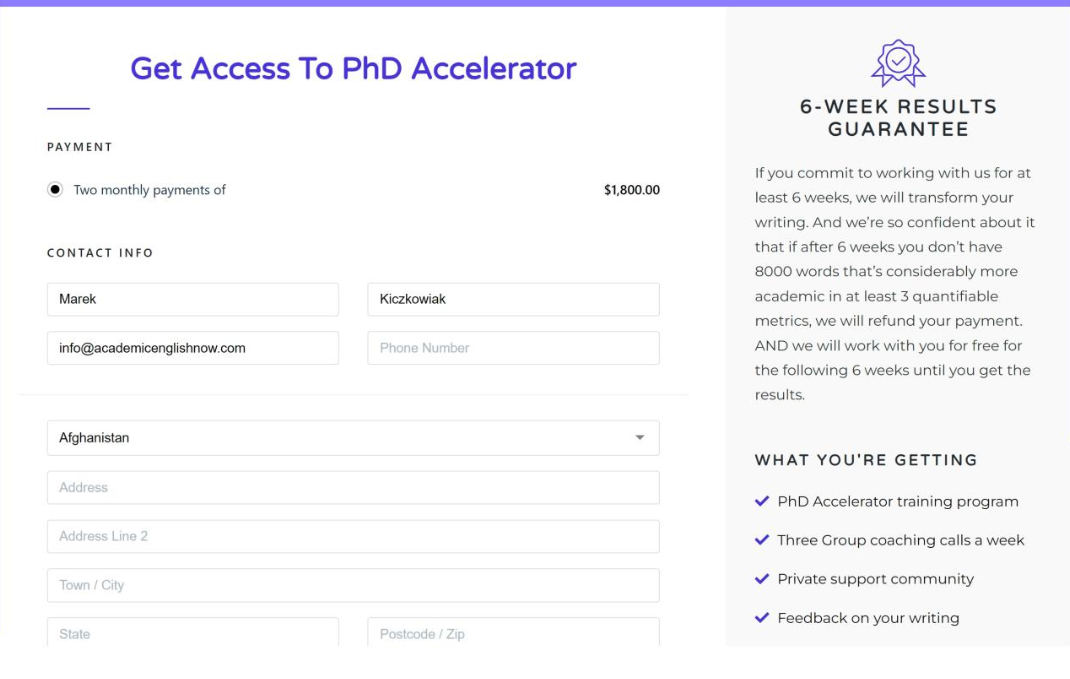
Kiczkowiak has morphed from teacher, NNEST crusader and teacher trainer in 2016 to CEO of Academic English Now in 2023. Currently, he’s charging “hundreds of students” $1,800 a month for his services and he’s very keen to“grow the business” as they say. My advice to all his potential clients is to look carefully at his credentials, his record and his products before handing over a cent. Read the form below carefully and get detailed information about “What you’re getting” (bottom right).
What exactly does the “training program” consist of?
What are “Group coaching calls”?
How many attend?
How long are they?
What’s the “Private support community”?
What does the feedback consist of?
What happens if I’m not satisfied?
An Unsatisfied Customer
I wrote to the person concerned, but I haven’t had a reply, so I won’t name her. I saw her correspondence with Kiczkowiak by going to his profile and looking at “Comments”.
Ms J., as I’ll call her, questions “the integrity of the program” and Kiczkowiak’s “true intentions”. She suggests that the program and the refund policy may prioritize financial gain over the well-being and satisfaction of clients.
In an open letter to Researchers and PhD candidates, Ms. J. shares her personal experience and provides a warning to those considering the PhD Accelerator Program offered by Kiczkowiak and his team. Ms. J says she joined the program out of desperation, without the chance to see any independent reviews which might have “revealed the truth about its actual value and efficacy”. She found the program’s claims of personalized action plans, tailored mentorship, and comprehensive support to be “misleading”, and she felt that the program failed to deliver on its promises, instead preying on the vulnerability and desperation of PhD students. She considers the cost of $2,400 to be “exorbitant” far outweighing the actual value provided, and warns about the difficulties of getting a refund: “the refund policy is designed to protect the program’s financial interests rather than prioritize client satisfaction”.
I understand that there was an exchange of comments between Miss J. and staff of Kiczkowiak’s “Academy”, including this from the boss himself:
Dear ……,
our refund policies are clearly stated on the website: https://academicenglishnow.com/terms-and-conditions The link to the terms is also available on the checkout page, and before purchasing, you have to click that you have read and agreed to the terms. The refund policy is also clearly stated on the right hand side (see the screenshot). Plus, you’re not really coerced to do anything. You can decide whether you want to enrol or not yourself. As I mentioned in my previous emails, we do not issue refunds that do not fit our refund policy, which is clearly disclosed. You also mentioned several times that the mentorship offered on the program was not up to standard. However, it’s important to point out here that you didn’t engage with your coach despite follow-ups from her.
Conclusion
Marek Kiczkowiak brags about selling “hundreds” of PhD candidates products that cost $1,800 a month. Not content with his current $70,000 a month income, he wants to attract a wider customer base, inviting EFL teachers everywhere to pay him a modest few thousand dollars so that he can lead them out of penury towards an annual income of $360,000! Wow! Can you believe it? I, for one, most certainly cannot.
The fifth run of our online TBLT course starts on 24th January 2024 and subscription is now open! Our last course was the busiest and best so far and we aim to top it in 2024. It’s a 100-hour, online tutored course aimed at
classroom teachersurse designers,
teacher-trainers,
directors of studies and
materials writers,
all of whom have an interest in upgrading their knowledge of this evidence-backed communicative approach with an eye to designing and implementing dynamic language courses based on relevant and engaging tasks.
The popularity of TBLT as an approach to language teaching is a response to a growing dissatisfaction among EFL professionals with current ELT practice. As convenient as coursebook-driven courses might be, they frequently fail to deliver the improvement that students hope for. TBLT focuses on meaning-making and engagement with real-world language needs; the courses give experienced teachers fresh opportunities to re-engage with their practice, they offer new teachers a more challenging, much more rewarding framework for their work, and they allow students to learn through scaffolded use of the language (learning by doing), which, as we know from evidence from research, is the best way to learn an L2.
The vibrancy of TBLT is evidenced by animated discussions on social media, by increasing presentations at conferences (including the biennial International Conference on TBLT), by the recently-formed International Association of TBLT (IATBLT), and by the wave of new publications, including thousands of journal articles, special issues in prominent journals, and the new journal specifically dedicated to the topic, TASK: Journal on Task-Based Language Teaching and Learning, the first volume of which appeared in 2021.
The Course
Our SLB course tries to “walk the talk” by working through a series of tasks relating to key aspects of TBLT, from needs analysis through syllabus and material design to classroom delivery and assessment. While we are influenced by Long’s particular version of TBLT, we also explore lighter, more feasible versions of TBLT which can be adopted by smaller schools or individual teachers working with groups with specific needs.
Neil McMillan (president of SLF) and myself (both experienced teachers with PhDs) do most of the tutoring, but we are privileged to be assisted by
Roger Gilabert: An expert on TBLT, Roger worked with Mike Long on several projects and has developed a TBLT course for Catalan journalists. His contributions to our four previous courses have been extremely highly rated by participants.
Marta González-Lloret: Marta did her PhD with Mike Long at the University of Hawai’i, is currently book series co-editor of Task-Based Language Teaching. Issues, Research and Practice, Benjamins, and is especially interested in using technology-mediated tasks. Marta has worked with Neil to strengthen Modules 3 & 4 and in this course; she will again give presentations, participate in a videoconferernce, and in the forums. As with Roger, she is a favorite with our participants.
The Modules
The whole course takes 100 hours and consists of five modules. You can choose individual modules or the whole course. If you choose to do one or two individual modules, you’ll have the chance to do further modules in later courses to achieve complete certification.
The 5 modules are:
Presenting TBLT
Designing a TBLT Needs Analysis
Designing a task-based pedagogic unit
Task-Based Materials:
Facilitating and evaluating tasks
Each module consists of:
Background reading.
A video presentation from the session tutor and/or guest tutors.
Interactive exercises to explore key concepts.
An on-going forum discussion with the tutors, guest tutors and fellow course participants.
An extensive group videoconference session with the tutors and/or guest tutors.
An assessed task (e.g. short essay, presentation, task analysis etc.).
The key text is Mike Long’s 2015 classic “SLA and Task-Based Language Teaching”. We are greatly indebted to Mike for his help and guidance, and in this course we’ll look closely at his strong version of TBLT, his materials, his ideas about “modified, elaborated texts”, and videos of presentations and videoconferences he made in previous courses.
More Flexible approach to TBLT
Thanks to the truly impressive work of the participants in the four previous courses, we’ve learned a lot about the problems of implementing a full version of Long’s TBLT, and we now better appreciate the need for a flexible case-by-case approach to the design and implementation of any TBLT project.
In the third and fourth courses, Neil’s careful re-organisation and tweaking of the moules made it increasingly possible for each participant to slowly develop their own TBLT agenda, working on identifying their own target tasks, breaking these down into relevant pedagogic tasks, finding suitable materials, and bringing all this together using the most appropriate pedagogic procedures.
Another gratifying aspect of all the courses is the way participants learn from each other; most of the individual participant’s TBLT models contain common elements which were slowly forged from the forum discussions.
So in this course, we’ll make even more effort to ensure that each participant works in accord with their own teaching context, and at the same time contributes to the pooled knowledge and expertise of the group.
Sneak Preview
To get more information about the course, and try out a “taster” CLICK HERE
Nothing in 2023 compares to Israel’s response to the Hamas-led attack of October 7th. As of today, according to Euro-Med Monitor, 85% of the population of Gaza (2,2 million) have been displaced, and the total number of Palestinian deaths in the Gaza Strip since 7 October is 21,731, including 8,697 children and 4,410 women as well as those missing and trapped under the rubble who are now presumed dead. Israel has increased the shocking extent of its targeting of civilians since the humanitarian truce collapsed, intensifying its complete destruction of residential areas and targeting schools that house thousands of displaced individuals in an apparent effort to increase the number of civilian victims. On a never-before-seen scale, Israel’s extensive bombing campaign has targeted both displaced civilians and civilian infrastructure, including hospitals, UN-run schools, mosques, churches, bakeries, water tanks, and even ambulances. On average, one child is killed and two are injured every 10 minutes during the war, turning Gaza into a “graveyard for children,” according to the UN Secretary-General. Almost 200 medics, 102 UN staff, 41 journalists, frontline and human rights defenders, have also been killed, while dozens of families over five generations have been wiped out.
“This occurs amidst Israel’s tightening of its 16-year unlawful blockade of Gaza, which has prevented people from escaping and left them without food, water, medicine and fuel for weeks now, despite international appeals to provide access for critical humanitarian aid. As we previously said, intentional starvation amounts to a war crime,” a team of UN experts wrote in a recent communique. They noted that half of the civilian infrastructure in Gaza has been destroyed, as well as hospitals, schools, mosques, bakeries, water pipes, sewage and electricity networks, in a way that threatens to make the continuation of Palestinian life in Gaza impossible. “The reality in Gaza, with its unbearable pain and trauma on the survivors, is a catastrophe of enormous proportions,” the experts said.
We must keep pressing for an immediate ceasefire and humanitarian aid. While the Gaza genocide continues, it feels trivial to discuss what’s happened this year in ELT, but here’s my personal take on how the year’s gone.
Evan Frendo: “English for the Workplace”
For me, the best event of 2023 was Evan Frendo’s Plenary, “English for the Workplace” at the IATEFL, 2023 conference. I did a post on it, based on Sandy Millin’s excellent notes (click the highlighted text above to see the post, which includes the video recording of Frendo’s talk), where I suggested that Frendo’s approach to ELT is revolutionary.
One of Frendo’s jobs is to help those who work in Vessel traffic service – the water equivalent of air traffic control. He used this example of “English for the workplace” to describe how he addressed the English needs of workers. What’s so revolutionary is that Frendo – and many of his colleagues – reject just about everything that typifies current ELT practice, at least as represented by IATEFL.
In Frendo’s world of “English for the Workplace”, they focus on “doing things in English”. Getting high marks in tests like IELTS has no place here, and neither do coursebooks. Standard English is replaced in practice by BELF: English as a business language Franca. As Frendo said:
“Conformity with standard English is seen as a fairly irrelevant concept. …. I don’t actually care whether something is correct or incorrect. As long as the meaning is not distorted. … BELF is perceived as an enabling resource to get the work done. Since it is highly context-bound and situation-specific, it is a moving target defying detailed linguistic description.”
Furthermore, the current CEFR idea of proficiency is challenged. In VTS communication, assessment is carried out by a team consisting of:
English teacher
Experienced VTS operator – say whether they’ve done the right thing
Legal expert- all conversations are recorded, but they can have legal implications
The test criterion is: Can the worker do the job? This chimes perfectly with what we, the advocates of TBLT, suggest.
Here’s the final slide:
Please have a look at my post and click the link to watch Frendo’s extremely well delivered plenary. It’s fantastic and it speaks of the future!
I see that Evan Frendo is a plenary speaker at TESOL Spain’s 2004 conference in March, 2024. As with IATEFL, I can’t believe that the TESOL organisation, which is so dominated by commercial interests, is giving the big stage to this eloquent critic of TESOL’s view of ELT. Never mind – let’s hear it for Evan!
ChatGPT (“generative, pre-trained transformer”)
The best laugh I had about all this was with Neil McMillan when he told me at a jolly restaurant dinner about his run-in with ChatGPT4 (he was probably using ChatGPX11Iaqz or something else I know nothing about) over a game of chess. Neil quickly reduced his opponent to gibbering apologies. “You said you knew the Scillian Defence”, says Neil after ChatGPT, playing White, made a beginner-like blunder. “I obviously have much to learn” says the robot. Three moves later Neil says “Now you’re in a right mess; it’s mate in two.” His opponent blurts out more apologies doing a good imitation of a cringing fraudster: “I do not have enough information; this is unlike the model …..”, and all that.
It’s still relatively easy to make a fool of any program that claims to understand the input they’re given, but obviously, AI is getting better very fast, and it’s going to have a big effect on how we do “education”. There are lots of ways this will play out, but let’s remind ourselves that in language learning, AI is up against one of its toughest problems, because language learning is uniquely complex. This raises the, for me anyway, still unresolved question of whether language learning is a process which is bootstrapped by a particular innate ability for language learning, as Chomsky suggests, or simply a process of using basic, low-level reasoning to use a massively redundant number of linguistic chunks / constructions.
I haven’t kept up with all that’s being done with ChatGPT, but I got off to a good start in February by attending a webinar led by Scott Thornbury where Sam Gravell and Svetlana Kandybovich gave us their well-informed opinions. I recommend it, and I’ve found following Sam Gravell on Linkedin very interesting and informative.
How to teach grammar
The most interesting book on ELT I’ve read this year is Ionin & Montril’s (2023) Second Language Acquisition: Introducing Intervention Research. It sets out to show how grammatical phenomena can best be taught to second language and bilingual learners by “bringing together second language research, linguistics, pedagogical grammar, and language teaching”. The authors assume a generative approach to language and language learning, and use intervention research methods to determine what kinds of pedagogic procedures are most efficacious. The first chapter gives a refreshingly clear discussion of explicit and implicit knowledge, learning and instruction, while Chapter 2 explains intervention research and grammar teaching. The next nine chapters look at how specific linguistic properties (articles, verb placement and question formation, argument structure, word order, ….) are acquired and have been investigated through intervention studies. To quote the authors:
“When we discuss the nature of the intervention, we will address the question of whether it involves primarily explicit or primarily implicit instruction and/or feedback. When we discuss the tests (pretests and posttests) that are used to measure what learners know before and after the intervention, we will note whether the tests are designed to target primarily implicit or primarily explicit knowledge. We will see that some studies manipulate the nature of the instruction as explicit vs. implicit, while others manipulate the tests in order to get measures of both explicit and implicit knowledge. Lichtman (2016) is an example of a study that did both. Many other intervention studies do not set out to manipulate or test the explicit/implicit distinction but are instead concerned with the efficacy of a particular pedagogical method or with applying linguistic theory to classroom research. Nevertheless, even for studies that do not focus on the explicit/implicit divide, it is important to consider whether the knowledge that the learners gain is primarily explicit or implicit, and whether this knowledge resulted from largely explicit or largely implicit instruction”.
In 2023, multilingualism and translanguaging continued to be a hot topics discussed in many assignments done by students enrolled in the University of Leicester’s MA in Applied Linguistics and TESOL, and maybe this reflects not just the sharp increase in the number of articles on these topics appearing in academic journals, but also discussion among teachers and teacher educators in blogs and the social media in general.
Both multilingualism and translanguaging begin with a questioning of how we define language; in particular, they question the assumption that to learn an additional language is to learn a separate, different “system”, comprising of a separate grammar, vocabulary and so on. They suggest that the “traditional approach” to language conceives of bi/multilingualism as the addition of parallel monolingualisms, and regards the hybrid uses of languages by bilinguals as signs of deviant or deficient language knowledge and use. Moving away from such traditional views, translanguaging theorists embrace Bakhtin’s view that “language is inextricably bound to the context in which it exists and is incapable of neutrality because it emerges from the actions of speakers with certain perspectives and ideological positions”. The move from a view of language as a discrete system to ‘languaging’ as a socially situated action is further developed by the construct of “translanguaging” (see, for example, Garcia & Wei (2014). Translanguaging scholarship began with an analysis of the historic conflict between English and Welsh in Wales; English being the dominant language imposed on Wales by English colonial rule, and Welsh being the indigenous language endangered by the colonial language policy which excluded Welsh from formal education spaces in Wales. It has since been expanded theoretically and practically by linguists and educators globally. Two facets stand out. First, García’s “dynamic bilingualism” (which emerges from her distinction between subtractive and additive bilingualism) insists that bilinguals choose parts from a complex linguistic repertoire depending on contextual, topical, and interactional factors. Translanguaging moves beyond languaging by affirming bilinguals’ fluent languaging practices and by aiming to transcend current boundaries of discourse so as to legitimise these hybrid language uses. Second, Li argues for the generation of translanguaging spaces, that is, spaces that encourage practices which explore the full range of users’ repertoires in creative and transformative ways.
There is an obviously radical agenda at work here: translanguaging foregrounds students’ multilinguistic knowledge and practices as “assets” and insists that these be fully utilized in classroom communication and in the wider community. Classroom praxis must exemplify the disruption of “subtractive” approaches to language education and “deficit” language policies. García & Wei (2014) emphasise the importance of “criticality, critical pedagogy, social justice and the linguistic human rights agenda” (p. 3), and of alignment with a socio-cultural perspective to applied linguistics.
“Standardized English” has become the focus of criticism from a wide range of scholars and researchers, and to those mentioned above, we should add Nelson Flores and Jonathan Rosa (see, for example, Flores & Rosa, 2015; Rosa & Flores, 2017) and Valentina Migliarini and Chelsea Stinson (see Migliarini & Stinson, 2021). Flores and Rosa argue that standardized linguistic practices are demonstrations of raciolinguistic ideologies, and that language education expects language-minoritized students to model their linguistic practices after the white speaking subject, “despite the fact that the white listening subject continues to perceive their language use in racialized ways” (Flores & Rosa, 2015, p. 149). Migliarini & Stinson (2021) use the Disability Critical Race Theory (DisCrit) solidarity framework “to challenge the deficiency lens through which students at the intersections of race, language, and dis/ability are constantly perceived”, arguing that this has “the potential to create more authentic solidarity with multiply marginalized students” (p. 711). DisCrit solidarity attempts to transform teachers’ understanding of power relations in the classroom “so that they are not steeped in color-evasion and silent on interlocking systems of oppression”. The framework also offers the opportunity to interrogate the ways ableism and linguicism reproduce inequities for students with disabilities. The DisCrit framework embraces translanguaging “as a strategic process (García, 2009b), theory of language (Wei, 2018), and as pedagogy (Garcia, 2009a) which conceptualizes the linguistic practices and mental grammar(s) of multilingual people” (Migliarini & Stinson, 2021, p. 713).
I remain mystified by all this stuff, and I’ve never seen or heard any coherent account of what it all means for the practice of ELT, i.e. a description of the radical, transformative changes which should be made to current syllabuses, materials, pedagogic procedures and assessment tools. And, at a more academic level, while I have no reason to think that any of the sources cited above intended the consequence, it’s a fact that most of the post graduate students I know who are drawn to the views and approaches sketched above are fervent in their commitment to sociolinguistics, and express hostility towards the work of psycholinguists working on cognitive theories of SLA, particularly those who claim to be carrying out scientific research. They frequently refer disparagingly to “positivism”, or to the “positivist paradigm” and express their support for “rebels” like Schumann, Lantolf, Firth & Wagner, and Block who, in the 1990s, tried to rock the positivist boat in which, they suggested, most SLA scholars so smugly sailed. I’ve done posts on this “social turn” during the year, deploring the relativist epistemology in particular and critical social justice in general. It’s particularly sad for me to see Professor Li Wei become Director and Dean of the Institute of Education, where I did my MA and PhD with Prof. Henry Widdowson, Guy Cook, Peter Skehan, and Rob Batstone.
References
Block, D. (1996). Not so fast: some thoughts on theory culling, relativism, accepted findings and the heart and soul of SLA. Applied Linguistics 17,1, 63-83.
Firth, A., & Wagner, J. (1997). On discourse, communication, and (some) fundamental concepts in SLA research. Modem Language Journal, 81,3, 285-300.
Firth, A., & Wagner, J. (1998). SLA property: No trespassing! Modem Language Journal, 82, 1, 91-94.
Flores, N., & Rosa, J. (2015). Undoing Appropriateness: Raciolinguistic Ideologies and Language Diversity in Education. Harvard Educational Review, 85, 2, 149–171.
Garcia, O. & Wei, L. (2014) Translanguaging: Language, Bilingualism, and Education. NY: Palgrave MacMillan.
Lantolf, J. P. (1996a). SLA Building: Letting all the flowers bloom. Language Learning 46, 4, 713-749.
Lantolf, J. P. (1996b). Second language acquisition theory building? In Blue, G. and Mitchell, R. (eds.), Language and education. Clevedon: BAAL/ Multilingual Matters, 16-27.
Lewis, G., Jones, B., & Baker, C. (2012a) Translanguaging: origins and development from school to street and beyond. Educational Research and Evaluation, 18, 7, 641-654.
Lewis, G., Jones, B., & Baker, C. (2012b) Translanguaging: developing its conceptualisation and contextualization. Educational Research and Evaluation, 18, 7, 655 – 670.
Migliarini, V., & Stinson, C. (2021). Disability Critical Race Theory Solidarity Approach to Transform Pedagogy and Classroom Culture in TESOL. TESOL Journal, 55, 3, 708-718.
Rosa, J., & Flores, N. (2017). Unsettling race and language: Toward a raciolinguistic perspective. Language in Society, 46, 5, 621-647.
Schumann, J. (1983). Art and Science in SLA Research. Language Learning 33, 49-75.
Books
These are the books I most enjoyed in 2023.
We are electric by Sally Adee
This is the best pop science book I’ve read for years. A “must read” that’s not only important but a real pleasure to read. Here’s the blurb:
You may be familiar with the idea of our body’s biome – the bacterial fauna that populates our gut and can so profoundly affect our health. In We Are Electric we cross the next frontier of scientific understanding: discover your body’s electrome.
Every cell in our bodies – bones, skin, nerves, muscle – has a voltage, like a tiny battery. This bioelectricity is why our brains can send signals to our bodies, why we develop the way we do in the womb and how our bodies know to heal themselves from injury. When bioelectricity goes awry, illness, deformity and cancer can result. But if we can control or correct this bioelectricity, the implications for our health are remarkable: an undo switch for cancer that could flip malignant cells back into healthy ones; the ability to regenerate cells, organs, even limbs; to slow ageing and so much more.
In We Are Electric, award-winning science writer Sally Adee explores the history of bioelectricity: from Galvani’s epic eighteenth-century battle with the inventor of the battery, Alessandro Volta, to the medical charlatans claiming to use electricity to cure pretty much anything, to advances in the field helped along by the unusually massive axons of squid. And finally, she journeys into the future of the discipline, through today’s laboratories where we are starting to see real-world medical applications being developed.
The New Puritans by Andrew Doyle
I don’t know of any really good book that cogently rebuts the theology of critical social justice, but “The New Puritans”, while a bit patchy, not always as well-argued as it could be, and relying on debateable core liberal values, does a good job of describing and evaluating the “religion of Social Justice”. “Cynical Theories” by Pluckrose & Lindsay makes a good companion, but it has an even more informal, clearly one-sided and less rigorous style.
The Wager by David Grann
“A real page turner!” “I couldn’t put it down!” Etc. This is the first David Grann book I’ve read, and now I’ve got the rest lined up. Here’s an Amazon review:
In the first half of the 18th century, Britain already had the most powerful navy in the world. But financing that navy was a huge burden on the Crown and England had not yet achieved the wealth that the industrial revolution and its own colonization efforts would later bring. The answer: intercept the gold and silver that Spanish ships were bringing home from its New World colonies.
Author David Grann is able to tell not only this larger story but also to resurrect one of the most astonishing seafaring events of the time. A ship named “The Wager” was to be part of a British fleet that would intercept gold-laden Spanish vessels in what was officially-sanctioned piracy. As the book’s cover indicates, what then transpired was shipwreck, mutiny and murder. This is also the story of unexpected survival and efforts in an Admiralty court back in England to establish the truth of what happened.
The Wager survived the perilous passage around the treacherous Cape Horn, only to run aground and break up on the rocks of an uninhabited island off Patagonia. There were no animals or other significant source of food on the island. The crew soon divided into two factions, one supporting Captain Cheap who wanted to build a vessel out of timbers salvaged from the shipwreck and continue up the Pacific coast of South America to engage Spanish ships. The other group was led by Buckeley, who wanted to build a vessel to return to England. The situation was so dire it would seem impossible that either group would survive.
Improbably a few men did make their way back to England to be hailed as heroes. That is, until a second group, including Captain Cheap, also arrived. This forms the final chapter of the story of The Wager and the launch of an inquiry to establish the truth.
Faced by death by hanging if they were found guilty of mutiny or of discipline if they failed their duty, each survivor told his story. “Members of the Admiralty found themselves confounded by competing versions of events,” the author tells us. The result was unexpected, but only if one fails to consider that the leaders of an institution, in this case the Royal Navy, have as their first priority the preservation of that institution and the protection of its reputation.
This is a wonderfully-written book; Grann certainly lives up to his reputation as a masterful story teller.
When we cease to understand by Benjamin Labatut
I’ve been meaning to read this for ages and it didn’t disappoint. Phillip Pullman calls it “a monstrous ad brilliant book”, William Boyd says it’s “mesmerising and revelatory”. It’s a dystopian nonfiction novel set in the present. It asks “Has modern science and its engine, mathematics, in its drive towards “the heart of the heart”, already assured our destruction?” It goes at a truly furious pace and before you know it, you’ve finished it. A few minutes sitting with the book on your lap looking out the window onto a nice rural landscape are recommended.
In my last post, I commented on the first strand of “recent, interesting research” which Penny Ur addressed at the 2023 IATEFL conference. She’s seen above getting a medal from someone who knows even less about SLA research than she does.
The research paper Ur referred to (de la Fuente & Goldenberg, 2022) is a well-written and well-considered report of a well-designed study, and it confirms the already widely-accepted view that using the L1 is often very helpful. But I doubt many of Ur’s audience needed to be persuaded that judicious use of the L1 is a “good thing”. On the other hand, I bet Ur didn’t point out that the school where the study was carried out is committed to a task-based learning approach (Ur dismisses TBLT as “unproven”), and I bet she didn’t refer to this bit at the end of the paper either:
An important question, and one that this study did not seek to address, is which types of L1 use (by students, by instructors) and which specific functions had a bigger impact on learning. In other words, what within the +L1 condition (principled approach to L1 use) accounts for the significant gains in learning? (de la Fuente & Goldenberg, 2022, p. 960).
Surely this is what needs discussion. The types of L1 use that work best depend too much on context for research to uncover any reliable, universal patterns. Consequently, we’re talking here about what Long (2015) calls a “pedagogic procedure”, and, as I argued recently in an exchange of views with Phillip Kerr, research into the efficacy of different pedagogic procedures should be carried out by groups of teachers who share the same context. (Ahem: teachers should be paid for this work, and the results should feed into, and hopefully improve, local teaching practice.)
Oral corrective feedback
Now this is a very, very important part of what teachers do.
Ur began by citing Lyster and Randa’s (1997) seminal study, “which showed that recast was the most common oral error correction technique used by teachers, but the least effective one”. That’s not a very accurate summary, but anyway, we’ll let it go and focus on the Big Question: Is it better to provide immediate correction, using relatively unobtrusive procedures such as recasts, or to provide more detailed correction after the task has been completed?
Ur cited studies by Li (2017) and Harmer, P. (2015) which concluded that learners prefer to be corrected at the moment they make the mistake. Ur then cited Fu and Li’s (2022) study, which claims the superiority of immediate corrective feedback. “The authors recommend correcting errors immediately after the first exposure to a new language item in order to rectify errors before they are proceduralized in the learner’s interlanguage”.
according to Sellivan, Ur said no more on the matter.
Discussion
In Long’s TBLT, oral corrective feedback is a vital part of the subservient but important role that explicit teaching plays. It’s a key component of “focus on form”, which is Long’s unfortunate name for his counter to a grammar approach that is based on a “focus on forms”. Long says that the best way to help students learn an L2 is to involve them in tasks where they “learn by doing”. However, since adults are, in Long’s opinion (an opinion which relies on Nick Ellis’ theory of SLA) “partially disabled” language learners, they benefit from a certain type of explicit instruction and intervention by teachers, and recasts are a key component. The gap – chasm! – between Ur’s and Long’s views on oral correction is hard to exaggerate.
Needless to say, Ur’s perfunctory treatment of “recent, interesting research” into oral corrective feedback gave the audience no insight into its significance, and nothing to chew on. In contrast, Leo Selivan went away, looked up the references, read the articles, thought about the issues, and made some interesting comments in his review. Good for him! But who else in the audience did anything similar? Leo could have emailed Ur and got the suggested reading list in 2 minutes, and the rest of the 2,000+ audience could have done something much better with the time they spent listening to Penny Ur smugly sharing her reading list.
The Fu and Li (2022) paper is worth discussion. It’s an excellent report of a study exploring the differential effects of immediate and delayed corrective feedback on the acquisition of the English past tense by 145 seventh-grade EFL students at a private school in Eastern China. The study is in, IMHO, extremely well-designed, well-reported and well-discussed. It includes discussion of two conflicting SLA theories: Long’s Interaction Hypothesis (Long, 2015), and Skill Acquisition Theory (Lyster, 2004). Long’s Interaction Hypothesis claims that feedback in the form of prompts such as recasts are ideal “because they withhold the correct form and encourage self-repairs according to which the optimal time to address linguistic problems is through critical feedback (CF) during negotiated interaction” (Fu & Lu, 2022, p.4). On the other hand, Skill Acquisition Theory (Lyster, 2004) emphasises the importance of feedback in “activating and proceduralizing the declarative knowledge which has been presented in the first stage of the teaching”.
Obviously, the two theories contradict each other, but there’s some convergence when it comes to the timing of corrective oral feedback. The Interaction Hypothesis insists that immediate feedback is superior, while Skill Acquisition Theory suggests that feedback can be provided during tasks performed immediately after explicit instruction, or postponed until a later time after learners complete some communicative practice. Given the authors’ and the school’s preference for TBLT, there was no explicit instruction phase prior to performance of the communicative task, and the study found that there was a marked advantage for unobtrusive, immediate critical feedback, including recasts. But the question of whether Long’s interaction hypothesis is a better explanation of L2 learning that skills acquisition theory remains. At least one of the two theories is wrong, and teachers would surely benefit from information about their relative merits and support from research findings. Furthermore, there are still scholars, including Rod Ellis and Peter Skehan & Pauline Foster, who argue for the importance of delayed, post-task feedback.
Conclusion
Penny Ur’s 2023 IATEFL talk was a waste of time, typical of what you get at conferences where the organisers blindly rely on “Big Names”. On the other hand, Leo Selivan’s blog post contributes much: he reports on the talk and gives us his considered view of the issues that Ur glided over.
Penny Ur’s session at the IATEFL 2023 conference was on Interesting recent research. It is, in my opinion, a good example of the poor quality of information that those responsible for teacher education provide the profession. Leo Selivan gave a full review of the session, and I rely on his report here.
Selivan says:
After defining what is meant by recent (the last 5-10 years) and what is considered interesting (what she personally finds interesting), in what followed Penny Ur bombarded the audience with highlights of no less than 30 research studies – all in under 25 minutes!
The studies she presented were divided into six strands:
Age and language learning
L1 in the language classroom
Oral corrective feedback
Inferencing meaning from context
The flipped classroom
The use of pictures
I’ll concentrate here on age and language learning. In a second post, I’ll discuss Ur’s hopeless attempts to inform teachers about the other strands.
Age and language learning
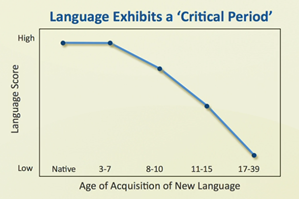
The popular belief that children are better foreign language learners has prompted educational policy makers around the world to advocate for an earlier start of foreign language instruction. However, Ur cites Carmen Muñoz’s (2006, therefore not “recent” by Ur’s own definition) Barcelona Age Effect (BAF) project which showed that in the foreign language classrooms of Barcelona’s primary and secondary schools, “age did not afford the same advantages as it does in a naturalistic language learning setting. Contrariwise, older learners (teenagers) may fare better”.
Ur also cites a review of research on the age factor by Muñoz and Singleton (2010, ditto) which argued that other factors contributing to learner success, including motivation, attitudes, affiliation with the L2 and the amount of exposure and quality of input have been largely ignored. Selivan summarises Ur as follows: “The kind of learning child learners are better at – implicit learning – requires vast amounts of exposure. Unfortunately, in a school setting with a couple of classes a week, exposure is woefully insufficient making it difficult for children to leverage implicit learning mechanisms”.
Finally, Ur cites Lightbrown and Spada’s (2020) paper which concludes that “studies in schools settings around the world have failed to find long-term advantages [ultimate attainment] for an early start …..”.
That’s all Ur had to say.
Discussion
What, I wonder, did the audience make of Ur’s treatment of this important issue? The point she hurriedly made was that research findings question the wisdom of educational policy makers who advocate for an earlier start of foreign language instruction. Not surprisingly, given her attempt to get into the Guiness Book of Records for the most research covered in a 25-minute talk, she neglected to attempt any critical evaluation of the cited research. So she neglected to say anything about what the participants in Muñoz’s study were taught.
Muñoz herself says little about the syllabus and teaching methods used in the English courses she reports on in her articles on the BAF project, and you have to read her book to find out that the courses in question were based on synthetic syllabuses which involve treating the target language as an object of study. The teachers involved in the BAF often had a low proficiency in oral communication, they talked for 70%+ of classroom time, frequently in their L1, and the students had few opportunities to use the target language, to engage in communicative tasks, to learn by doing. Thus, students were taught about the target language far more than they were helped to use it and the tests measured what they knew about the language more than how well they could use it for spontaneous communication. Given all this, it’s hardly surprising that the older students learned what they were taught faster and better than the young ones, because, as Carmen herself indicates, young children rely on implicit learning which leads to procedural knowledge and consequent communicative competence, while older students are more receptive to explicit learning which leads to far less useful declarative knowledge.
So “earlier is better” as an educational policy is only mistaken if ELT is based on the sort of ELT you find in Catalan public schools, which is probably a representative model of how it’s taught just about everywhere. Older children are better than younger children at learning about the language, which is not, in my opinion, what – or how – they should be taught.
The still controversial “Critical Period Hypothesis” (which these days is explored in terms of “sensitive periods”) needs explaining to teachers, and its implications for ELT need attention. Teachers need to be involved in discussions about the research which suggests that young children learn additional languages in the same way that they learn their native language or languages: they make sense of the formal aspects of the additional target language for themselves while being exposed to, and interacting with others in that language. Meanwhile, the research suggests that older students learn slightly differently. If we accept (still disputed) research findings of senstive periods, then the putative windows of purely implicit learning of certain features of the additional target language close by the time children reach the age of 14 or so (the window for pronunciation is said to close at around 8 years old!). In which case, they, like adult learners, need more explicit teaching which pays attention to these features.
Ur did precisely nothing to help teachers appreciate the issues involved in research into how age affects SLA, and I doubt that she did anything to make teachers think about its implications. She was given the biggest stage, star billing and, no doubt, all expenses paid. In his review, Selivan waxes lyrical about Ur’s ability to “make research sound sexy”; he applauds her audacity at seeking to cover so much ground; he drools that he was so “fired with enthusiasm” to report on this session that he made it his “only write-up from IATEFL 2023”. It’s enough to make you weep!
In his recent post, Perspectives on language teaching research, Phillip Kerr argues that attempts to get language teachers more interested in language teaching research are unlikely to succeed. He takes readers on “a little detour” to talk about the philosophy of measurement, which unfortunately consumes most of the text, leaving us with the rather bald and unoriginal claim that researchers are interested in precision, while teachers are interested in more general take-aways that can be easily applied in their lessons. Kerr concludes that it’s hard not to share Widdowson’s skepticism, voiced in a recent webinar (Widdowson & Yazdi-Amirkhiz, 2023), about the practical relevance of SLA research. Surely Widdowson is right to say that all efforts have so far failed to do anything about “‘the tenuous link between research and practice’ (Hwang, 2023) or to bridge the ‘gap between two sharply contrasting kinds of knowledge’ (McIntyre, 2006)”. I would like to challenge this view by briefly summarizing some of the arguments put forward in the first part of Jordan and Long (2023), where SLA research and its implications for English Language Teaching (ELT) are considered.
Before I begin, a quick comment on the following assertion of Kerr’s: “There is a clear preference in academia for quantitative, empirical research where as many variables as possible are controlled. Research into language teaching is no different”. One is tempted to ask where Kerr has been for the last twenty years, but we know he keeps up with research, and indeed his references make it clear that he’s perfectly well aware of the “social turn” that research into language teaching has taken. So he really ought to know that it’s simply false to say that currently there is a clear preference in academia for quantitative empirical research into language teaching.
To the issue, then.
In the first five chapters of Jordan and Long (2022), a summary of research in SLA is given. In Chapter six, we discuss what we consider to be the most important general implications for ELT.
Interlanguage
We begin by discussing interlanguage, which is an individual learner’s transitional version of the target language. Iinterlanguages share much in common, but each is to some extent idiosyncratic; they are the psycholinguistic equivalent of idiolects, but they differ in being unstable, exhibiting considerable variability, especially in the early stages. The variation is synchronic and diachronic. The learner’s native language (L1) influences many aspects of L2 development, both positively and negatively. Learners make many morphological errors in English as they progress, the result of overgeneralization, overuse, omission, and substitution; rather than something to be avoided through textbook writers and teachers exercising tight control over students’ speaking opportunities, they constitute an inevitable and productive part of the L2 acquisition process. Naturalistic, instructed, and “mixed” learners exhibit somewhat different error patterns as their proficiency increases.
Developmental Sequences
Studies have repeatedly demonstrated that learners follow the same developmental routes. They master the structures in roughly the same manner and order, whether learning in classrooms, on the street, or both. Attempts to make learners skip a developmental stage fail, leading Pienemann to formulate his Processability, Learnability, and Teachability Hypotheses: what is processable by students determines what is learnable, and what is learnable determines what is teachable (Pienemann, 2015). The effectiveness of feedback on error has been shown to be constrained in the same way. Learners analyze the input and come up with their own interim grammars, their progress broadly conforming to the developmental sequences observed in naturalistic settings.
A basic finding from decades of research is that, contrary to what is commonly believed, learners play a more powerful role in their own language learning than either teachers or coursebook writers. Students are not empty vessels waiting for grammatical structures and vocabulary items to be hammered into them one by one in a pre-set, fixed order, through a combination of rules and drills. Nor do they learn one structure or word at a time, moving from ignorance to native-like command of the item in one step, and then moving on to the next, as most commercial coursebooks imply. Language learning is slow and incremental, with many errors, transitional structures, and gradual approximations to correct forms and uses along the way. No matter the L1 or the order or manner in which target language structures are presented to them, however, learners analyze the input and come up with their own transitional IL grammars, development broadly conforming to developmental sequences observed in naturalistic settings.
Rate of Development
In Chapter 3 we discuss seminal findings in SLA research which demonstrate that that instruction can speed up adult second language acquisition. My very brief summary here doesn’t include a description of them or the references. Sorry. The positive effects of instruction on rate of development might, at first glance, seem at odds with its lack of effect on developmental sequences. The two sets of findings can be reconciled, however, when it is remembered that developmental sequences are based on implicit knowledge, subject to universal cognitive constraints. Instruction speeds up that development, without altering the sequences, through devices such as increasing the perceptual salience of and exposure to items that might otherwise take a long time for learners to notice. This draws students’ attention to them sooner, but also when they are psycholinguistically ready.
Ultimate L2 attainment
Contrary to what the robustness of interlanguage processes and developmental sequences might suggest, teaching can have very positive effects on rate of development and, potentially, on ultimate L2 attainment. Long-term advantages for instruction are probably due to (selective, constrained) use of explicit L2 knowledge, the increased perceptual salience that instruction brings to problematic items, and appropriately modified input. Long-term benefits of instruction are hard to demonstrate unambiguously, not least because learners who have achieved very advanced proficiency in an L2 through purely naturalistic learning are rare – or at least (not necessarily the same thing), have rarely figured in SLA research. But the common sequences in which new structures emerge, regardless of the type of instruction learners receive or, indeed, whether they receive instruction at all, show that ultimately, teachers are facilitators, not controllers, of their students’ language learning – partners, not masters, guides, not god.
Cognitive Processes in SLA
The same basic cognitive processes involved in all different kinds of human learning are implicated in language learning. Incidental, intentional, implicit, explicit, and automatized explicit learning are present across the life span, although their relative power and importance varies somewhat according to the learner’s age, as well as with the kind of instruction and kind of L2 exposure he or she experiences. There is an overwhelming consensus among SLA researchers that implicit knowledge is of overriding importance for a functional command of a second language. Implicit knowledge is unconscious knowledge and it results in the ability to use the language to function fast, fluently, and effortlessly. Implicit learning is more basic, more important than explicit learning, and superior. Access to implicit knowledge is automatic and fast; it is what underlies real-time listening comprehension (e.g., attending a university lecture or watching a TV news broadcast), spontaneous speech, and fluency. It is also more durable than explicit knowledge. Two statistical metaanalyses of dozens of studies comparing short-term (immediate post-test) and long-term (delayed post-test) learning from implicit and explicit negative feedback (Goo & Mackey, 2007; Li, 2010) and another of implicit and explicit instruction as a whole (Kang et al, 2018) have found that explicitly induced gains tend to fade fairly quickly, whereas implicitly induced gains mature and increase over time. The reasons for the long-term advantage of implicit knowledge are as yet unclear, but probably reflect the deeper processing and/or the greater number of encounters with target forms and constructions that implicit learning requires. Implicit learning, on the other hand, demands more from the learner – deeper processing. It occurs incidentally, while their primary focus is on meaning, e.g., understanding a story they are listening to and/or reading and/or watching. Probably my most insistent argument over the years has been that implicit learning needs to be prioritized in language teaching to a far greater extent than is typical in traditional, coursebook-driven teaching.
Implications for ELT
SLA research shows that teaching cannot change language-learning processes, which are universal. Nor can it alter the developmental sequences that students follow, i.e., the route of acquisition, which is broadly the same for naturalistic and instructed learners, regardless of their age and L1 background. Nevertheless, while instruction is quite limited in its effects where processes and sequences are concerned, it can be effective in other areas. As we saw, instruction can improve the rate at which learners progress, and probably, the level they eventually achieve in the L2. Both are obviously matters of considerable practical importance to learners and teachers, alike. More generally, we can draw four interrelated implications:
(1) Give priority to incidental and implicit language learning inside and outside the classroom;
2) Use an analytic, not a synthetic, syllabus;
(3) Respect developmental processes, sequences, and learnability; and
(4) Change the structure of classroom discourse.
In Section 2 of the book we discuss specific applications of these generalizations to syllabus design, materials design, classroom pedagogy, and assessment. We argue that coursebook-driven ELT ignores the four implications stated above, and is therefore inefficacious, while the strong version of TBLT described by Long (Long, 2015) takes careful notice of all these implications, and is thus likely to be far more efficacious.
Conclusion
Finally, Kerr is right to say that Widdowson expresses skepticism about the practical relevance of SLA research, but, as usual, it’s not that simple with Widdowson. Here’s part of what he said at the plenary:
Despite the teachers’ best efforts and all the various methods and approaches that have been proposed over the years, learners still persistently fail to conform. So why is it that learners so often are not persuaded to do what they are taught to do? What is their problem? It clearly hasn’t been solved, or indeed even addressed, by an orthodox competence-based way of thinking which is focused on the teaching objective, and institutional measurement of achievement.
I would suggest that the main problem for learners is essentially one that is pedagogically imposed upon them, because their learning is actually impeded by the very teaching that is meant to promote it (Widdowson & Yazdi-Amirkhiz, 2023, p. 397).
To what extent, I wonder, does Kerr’s Inside Out coursebook series impede or promote the kind of learning and teaching Widdowson is advocating?
References
Jordan, G. & Long, M. (2022). English Language Teaching: Now and How it Could Be. Cambridge Scholars.
Pienemann, M. (2015)An Outline of Processability Theory and Its Relationship to Other. Approaches to SLA. Language Learning, 65, 1, 123-151.
Widdowson, H. & Yazdi-Amirkhiz, S.Y. (2023). Webinar on the subject of English and applied linguistics. Language Teaching, 56, 3, 393 – 401.
JPB Gerald was recently interviewed by Anna Roderick (editor in-chief at Multilingual Matters) about his book “Antisocial Language Teaching” in the “Ask the Author” series. About 19 minutes in, talking about different reactions to his book, Gerald says he wasn’t surprised that a lot of people really liked his book, but that he wasn’t surprised either that some people “were just mad” because “they were always going to be mad”. Then he referred to me.
The “I’ve told the story so often I now believe it’s true” Version
“There was one guy who followed me round the internet to talk about how bad my work was, mostly because I called him a racist once before this and then he was mad for two years. And I’m like “You’re proving my point, man, you’re proving my point”, although he weirdly said one day “I won’t do this anymore”. I don’t know,… I don’t know, maybe he had a change of heart although I don’t think he had a change of heart, I think he just decided to shut up. Wierd.
The Facts
During an exchange of emails last December, at 12.38 am on 24/12/2022, Gerald sent me an email which ended:
I will stop mentioning you on twitter if you stop writing about me. A fair truce.
At at 1.11 am on 24/12/2022, I sent Gerald an email which ended:
from today I won’t mention your name on Twitter or any other social media channel again, and I won’t make any further comments on your published work.
The social sciences (social anthropology, sociology, psychology, political science, and economics are the main players) have had an uneven record when in comes to assessments of their academic achievements, and those within its ranks who regard the label as an oxymoron have contributed particularly loud and disruptive dents to its reputation. The recent enormous growth of the “anti-science” faction in the social sciences worries many, including me, and here I take a look at how we’ve arrived at this sorry state in my particular neck of the woods.
The development of modern sociology, including sociolinguistics, raciolinguistics, and Critical theories.
The Strong Programme
In 1976 the sociologist David Bloor argued that all systems of belief are equivalent, and that “knowledge is whatever men take to be knowledge.” (Bloor, 1976, 1). Bloor distinguished between knowledge and belief by reserving the word “knowledge” for “what is collectively endorsed, leaving the individual and idiosyncratic to count as mere belief” (Bloor, 1976, 2-3). If we follow Bloor, then the knowledge found in scientific theories is socially determined and thus unable, like all attempts to understand the world, to make any claims to objective truth.
Quantum mechanics is often given as an example of a “socially-determined belief”. Forman (1971, in Gross and Levitt, 1998) suggested that quantum mechanics was the result of the social conditions in Germany after their defeat in World War I, which led German public opinion to an anti-intellectual, anti-science stance. Since the principle of causality was an archetypical example of pre-war attitudes of scientists, Forman claimed, apparently in all seriousness, that quantum mechanics was enthusistically taken up as a field of investigation by German physicists interested in the behaviour of matter and light on the atomic and subatomic scale not because of its ability to contribute to the science of physics but because it did not require all physical events to be caused and therefore chimed with the glooomy post war Zeitgeist.
Even more outrageous is sociologist Ferguson’s explanation of the paradigm shift in physics which followed Einstein’s publication of his work on relativity.
The inner collapse of the bourgeois ego signalled an end to the fixity and systematic structure of the bourgeois cosmos. One privileged point of observation was replaced by a complex interaction of viewpoints.
The new relativistic viewpoint was not itself a product of scientific “advances”, but was part, rather, of a general cultural and social transformation which expressed itself in a variety of modern movements. It was no longer conceivable that nature could be reconstructed as a logical whole. The incompleteness, indeterminacy, and arbitrariness of the subject now reappeared in the natural world. Nature, that is, like personal existence, makes itself known only in fragmented images. (Ferguson, cited in Gross and Levitt, 1998: 46)
Thus, rather than see Einstein’s relativity theory as a more powerful theory of physics offering an improved explanation of the phenomena in question, Fergason sees it as a representation of the evolution of “bourgeois consciousness”.
A third example is Latour and Woolgar’s 1979 paper, Laboratory Life: The Social Construction of Scientific Facts, (discussed in Gross and Levitt, 1998) which described the work of the scientists at Latour’s laboratory as the “collective construction” by a group of scientists of a theory which used “conventions” agreed among themselves. Latour and Woolgar claimed to have “unmasked” what the deluded scientists regarded as disinterested attempts to explain phenomena by appealing to empirical data collected by controlled experiments, by describing them as being no more than the joint invention of a myth. Latour (1985, 1988) went on to argue that scientists use language to construct a particular kind of discourse: the use of particular kinds of concepts taken as uncontroversial by the scientific community, the use of references, quotations and footnotes, the structuring of scientific articles, all play their part in legitimising the output of scientists and disguising their subjective nature. In short, science is an arrogant bogey-man, the methodology it recommends takes us away from a proper “understanding” and “appreciation” of ourselves and traps us inside an arid alienated framework.
The basic argument of all the examples above is that scientific knowledge is not powerful because it is true; it is true because it is powerful. The question should not be “What is true?”, but rather “How did this version of what is believed to be true come to dominate in these particular social and historical circumstances?” Truth and knowledge are culturally specific. Acepting this argument brings us to the end of the modern project, and situates us in a “post-modern” world. As Lois Shawver, the influential postmodernist figure, puts it, “Postmodernism begins with a loss of faith in the dreams of modernism.” She continues: “In place of the lost dream of modernism, postmodernism gives us a new vocabulary, a new language game, for helping us notice dimensions of experience that were obscured by the modernist vision. It’s a dynamic language game, with meanings evolving and changing” (Shawver, 1997, 372).
Constructivism
The next step was social constructivism. While differences among them exist, what the constructivists seem to have in common is their opposition to the idea of objective truth. Denzin and Lincoln (1998) explain:
Knowledge and truth are created, not discovered by mind. Constructivists emphasise the pluralistic and plastic character of reality – pluralistic in the sense that reality is expressible in a variety of symbol and language systems; plastic in the sense that reality is stretched and shaped to fit purposeful acts of intentional human agents. They endorse the view that “contrary to common sense, there is no unique “real world” that pre-exists and is independent of human mental activity and human symbolic language” (Bruner, 1986). In place of a realist view of theories and knowledge, constructivists emphasise the instrumental and practical function of theory construction and knowing. (Denzin and Lincoln, 1998: 7)
Lincoln and Guba’s constructivist philosophy is idealist (they assume that “what is real is a construction in the minds of individuals”), pluralist and relativist: “There are multiple, often conflicting, constructions and all (at least potentially) are meaningful. The question of which or whether constructions are true is sociohistorically relative” (Lincoln and Guba, 1985: 85).
Brinner (1999) developed her idea of constructivism from an educational perspective. She rejected the accepted realist view of epistemology because it sees knowledge as a passive reflection of a putative external, objective reality. Realists take the naive view that our senses work like a camera that projects an image of how the world is onto our brain, and use that image as a map of the objective structure “out there”, but this view ignores “the infinite complexity of the world”. Detailed observation reveals that “the subject is actively generating plenty of potential models, and that the role of the outside world is merely limited to reinforcing some of these models while eliminating others”.
The final step is the development of “critical” theories, including Critical Social Justice theories (CSJ), which I briefly discussed in the previous post. CSJ aims to vanquish the prejudice and discrimination people suffer based on characteristics like race, sex, sexuality, gender identity, dis/ability and body size. Like the constructivists, CSJ theorists and activists see all knowledge as socially constructed, but they take an additional step by asserting that the culturally constructed knowledge which pervades today’s world serves to maintain oppressive power systems. This is achieved by dominant groups in society legitimising certain kinds of knowledge which are perpetuated by ways of talking about things – discourses. While all knowledge is socially constructed, CSJ theorists and activists believe that they can see beyond the ideologically tainted discourses which powerful groups (white, male heterosexuals, for example) engage in because of their active engagement in the fight to liberate the undervalued groups whose identities are systematically repressed and denied by the oppressors.
Discussion
My argument is that sociolinguists working in the field of applied linguistics who adopt a relativist epistemology of the type described above are fundamentally mistaken, and, furthermore, their work has a detrimental effect both on education and on progressive attempts to fight neoliberal capitalism.
I define relativism as the view that there is no objective reality; that the way we perceive the world depends on who and what we are, and where and when we live; and that there is no rational standard of judgement that can be used to decide between opposing theories which attempt to explain the same phenomena.
Rationalism
First, let me state my own position. I think the best way to improve our understanding of the world is to adopt a realist epistemology and rely on logic, rational argument and empirical observation to construct and evaluate theories. To quote from my 2004 book on theories of SLA.
A. Assumptions
An external world exists independently of our perceptions of it. It is possible to study different phenomena in this world, to make meaningful statements about them, and to improve our knowledge of them. This amounts to a realist epistemology.
Research is inseparable from theory. We cannot just observe the world: all observation involves theorising.
Theories attempt to explain phenomena. Observational data are used to support and test those theories.
Research is fundamentally concerned with problem-solving. Research in SLA should be seen as attempted explanations. Theories are explanations and are the final goal of research.
We cannot formalise “the scientific method”. There is no strict demarcation line between “science” and “non-science”: there is no small set of rules, adherence to which defines the scientific method.
B. Methodology
We start with hypotheses that explain the phenomena in question. We test the hypothesis trying as hard as we can to falsify it. To the extent that our attempts fail, we can accept the hypotheses as tentatively true.
C. Criteria for the evaluation of SLA theories
Research, hypotheses, and theories should be coherent, cohesive, expressed in the clearest possible terms, and consistent
Theories should have empirical content. Propositions should be capable of being subjected to an empirical test so that hypotheses can be supported or refuted..
Theories should be fruitful. They should make daring and surprising predictions, and solve persistent problems in their domain.
Theories should be broad in scope.Ceteris paribus, the wider the scope of a theory, the better it is.
Theories should be simple. Following the Occam’s Razor principle, ceteris paribus, the theory with the simplest formula, and the fewest number of basic types of entity postulated, is to be preferred for reasons of economy.
I should add Popper’s defence of objective knowledge. Whatever motives scientists had for doing what they did, and taking the decisions they did, they gave us theories, and this is the basis of objective knowledge, what Popper (1972) refers to as “World Three”:
We may distinguish the following three worlds or universes: first the world of physical objects or of physical states; secondly the world of states of consciousness, or of mental states, or perhaps of behavioural dispositions to act; and thirdly, the world of objective contents of thought, especially of scientific and poetic thoughts and of works of art. (Popper, 1972: 106)
Developing this idea, Popper says:
In our attempts to solve problems we may invent new theories. These theories, again, are produced by us; they are the product of our critical and creative thinking, in which we are greatly helped by other existing third-world theories. Yet the moment we have produced these theories, they create new, unintended and unexpected problems, autonomous problems, problems to be discovered.
This explains why the third world which, in its origin, is our product, is autonomous in what may be called its ontological status. It explains why we can act upon it, and add to it or help its growth, even though there is no man who can master even a small corner of this world (Popper, 1972: 161).
Relativism
As opposed to rationalists, there are those in the sociolinguistic domain who adopt a relativist, social constructivist position. As we have seen, this involves denying the possibility of knowing any objective reality external to the observer, and claiming that there is a multiplicity of realities, all of them social constructs. The adoption of the view that the construction of reality is a social process means that there can be no one “best” theory of anything: there are simply different ways of looking at, seeing, and talking about things, each with its own perspective, each with its own set of explicit or implicit rules which members of the social group construct for themselves. Science is just one specific type of social construction, a particular kind of language game which has no more claim to objective truth than any other. Let’s look at a few short examples of this point of view.
Schumann (1983) suggests that SLA research should be viewed as both art and science. As an example of the artistic perspective Schumann suggests viewing the opposing accounts of Krashen and McLaughlin of conscious and unconscious learning as
two different paintings of the language learning experience – as reality symbolised in two different ways… Viewers can choose between the two on an aesthetic basis, favouring the painting which they find to be phenomenologically true to their experience (Schumann, 1983, 74).
Lantolf (1996) suggests that scientific theories are metaphors, that the acceptance of “standard scientific language” within a discipline “diminishes the productivity of the scientific endeavour” and that “to keep a field fresh and vibrant, one must create new metaphors” (Lantolf, 1996, 756).
Firth and Wagner (1997) argue that SLA research should be “reconceptualiized” so as to “enlarge the ontological and empirical parameters of the field”. They continue:
We claim that methodologies, theories and foci within SLA reflect an imbalance between cognitive and mentalistic orientations, and social and contextual orientations to language, the former orientation being unquestionably in the ascendancy (Firth and Wagner, 1997, 143).
At the end of their paper, they say:
although SLA has the potential to make significant contributions to a wide range of research issues, that potential is not being realised while the field in general perpetuates the theoretical imbalances and skewed perspectives on discourse and communication (Firth and Wagner, 1997, 285).
Block (1996) argues that the field of SLA is under the sway of a ruling ideology, and in the course of a plea for a wider view of SLA research, Block challenges some central assumptions held by what he sees as the ruling clique. The assumptions that Block objects to include that there is any such thing as “normal science”, that a multiplicity of theories is problematic, that replication studies are helpful, and that there is an “ample body” of “accepted findings” within SLA research. Finally Block argues that one problem for the SLA community, which stems from its being under the sway of such misleading assumptions, is that those who attempt to challenge them do not get a fair opportunity to voice and promote their alternative views.
Discussion
When Firth and Wagner (1997) argue for “a reconceptualization of SLA research that would enlarge the ontological and empirical parameters of the field”, they would seem to be making a plea for more attention to be paid to sociolinguistics and discourse analysis, and for SLA research to be liberated from the domination of “Chomskian thinking.” But there is another argument in the Firth and Wagner paper, namely that those working in psycholinguistics are dominated by the views of a small group of researchers who insist that SLA research be carried out according to “established” and “normal” scientific standards. Firth and Wagner argue that there is something deeply wrong with such a position, and they go on to suggest that SLA research should throw off the assumptions of scientific enquiry and adopt a relativist epistemology which holds that there is not one reality, that all science is political, that all statements are theory-laden, that theories are a kind of story-telling, and so on. Here the two separate issues mentioned above have become tangled up. As Long puts it: “Firth and Wagner attempt to bolster their “social context” case by an unfortunate appeal to epistemological relativism thereby conflating what are two separate issues” (Long, 1999: 3).
Block (1996) makes exactly the same mistake as Firth and Wagner. Block claims that those who attempt to challenge the ruling clique in SLA do not get a fair opportunity to voice and promote their alternative views, and at the same time he claims that the field of SLA is dominated by a certain methodological orthodoxy which should be replaced by a more relativistic alternative. Again, we must separate the issues.
To argue for a shift in focus for SLA research is one thing. To argue that there is no rational way to decide that Theory X is better than Theory Y is another, separate thing. The first issue is a political question about priorities in the distribution of limited research resources, the second issue is about the fundamental questions of what we can know, and of how we should do research. The relativists have every right to argue for more resources to be devoted to their kind of research, and to argue the merits of their kind of approach to theory construction and assessment. But they should clearly separate what are, I repeat, two different issues.
Regarding the epistemological issue, as an example we can take the suggestion that scientific theories are metaphors, that the acceptance of “standard scientific language” within a discipline “diminishes the productivity of the scientific endeavour” and that “to keep a field fresh and vibrant, one must create new metaphors.” Nobody, I suppose, would question that terms like “input” “processing” and “output” are metaphors, and it is certainly worth reminding oneself that they are metaphors. But, from my side of the fence, scientific theories are not just metaphors, they are attempted explanations of events that take place in a real world and they must be open to empirical tests which support or falsify them so as to enable us to choose rationally between them. I have no particular objection to looking at Krashen’s and McLaughlin’s theories as “paintings”, as reality symbolised in two different ways, but sooner or later we will need to scrutinise the two opposing theories in order to check their validity, and to subject them to empirical tests. On the basis of such scrutiny, by uncovering ill-defined terms, contradictions, etc., and by seeing how they stand up to empirical tests, we will be able to evaluate the two accounts and make some tentative choice between them. First, they cannot both be correct: McLaughlin suggests that conscious learning affects language production, while Krashen denies this. Second, they suggest different ways of continuing the search for answers to the question of interlanguage development, and different pedagogical applications, and researchers have to have some reasons to choose between them. Krashen’s account is seriously flawed since, first, its terms are almost circular, and second, there is very little empirical content in it These, to the rationalist, are extremely serious defects. Schumann suggests that: “Neither position is correct; they are simply alternative representations of reality” (Schumann, 1983: 75). It may well turn out that neither position is correct, and they are certainly alternative representations of reality, but if the implication is that there is no way, other than an appeal to our own subjective aesthetic sense, to decide between them, then here lies the fundamental disagreement between rationalists and extreme relativists.
Where those discussed above who adopt a relativist epistemology are mistaken is in their assumption that their political analysis has necessary implications for the veracity or otherwise of any particular theory. And where they fail miserably is in the alternative they offer to a rationalist research programme. When one looks at the world from their perspective, what are the results in terms of their explanations? No causal explanations are allowed: all attempts to explain, refute, establish, confirm, etc., are deconstructed and exposed as the logocentric-serving myths that they are. The task is to undermine, and overcome not just science but language and common sense. To what end? Culler, a committed postmodernist, claims that “The effect of deconstructive analyses, as numerous readers can attest, is one of knowledge and feelings of mastery” (Culler, 1992, cited in Searle 1993: 179). Searle comments: “The trouble with this claim is that it requires us to have some way of distinguishing genuine knowledge from its counterfeits, and justified feelings of mastery from mere enthusiasms generated by a lot of pretentious verbosity” (Searle, 1993: 179).
Science is certainly a social institution, and scientists’ goals, their criteria, their decisions and achievements are historically and socially influenced. But this does not make the results of social interaction (in this case, a scientific theory) an arbitrary consequence of it. Popper defends the idea of objective knowledge by arguing that it is precisely through the process of mutual criticism incorporated into the institution of science that the individual short-comings of its members are largely cancelled out.
As Bunge (1996) points out “The only genuine social constructions are the exceedingly uncommon scientific forgeries committed by a team” (Bunge, 1996: 104). Bunge gives the example of the Piltdown man that was “discovered” by two pranksters in 1912, authenticated by many experts, and unmasked as a fake in 1950. “According to the existence criterion of constructivism-relativism we should admit that the Piltdown man did exist – at least between 1912 and 1950 – just because the scientific community believed in it” (Bunge, 1996: 105). Here is the heart of the confusion for all those who take a radically relativist position: the deliberate confusion of two separate issues: claims about the existence or non-existence of particular things, facts and events, and claims about how one arrives at beliefs and opinions. Whether or not the Piltdown man is a million years old is a question of fact. What the scientific community thought about the skull it examined in 1912 is also a question of fact. When we ask what led that community to believe in the hoax, we are looking for an explanation of a social phenomenon, which is a completely separate issue. Just because for forty years the Piltdown man was supposed to be a million years old does not make him so, however interesting the fact that lots of people believed it might be.
Paul Boghossian remarks that the class of things that can be labelled social constructions is enormous: nation states, the dollar, university education and the BBC are random examples. Anything that could not have existed without societies defines the class, and likewise, anything that actually does or did exist independently of societies cannot be a social construction, dinosaurs, giraffes and proteins are examples. “How could they have been socially constructed, if they existed before societies did?” (Boghossian, 2001: 7). Yet it is precisely this obvious distinction that is ignored by those who claim that our beliefs are all we have, and that we can have no knowledge of anything that exists independently of them. Latour and Woolgar’s study (1979) referred to above is a good example. While it might very well be the case that we believe that dinosaurs existed and that DNA exists today because the scientists tell us so, it remains, for those who want to take a realist, rationalist view of the world at least, an independent question of fact as to whether or not such things exist, i.e., whether or not our beliefs are true or false.
It is when constructivists insist on a radically relativist epistemology, when they rule out the possibility of data collection, of empirical tests, of any rational criterion for judging between rival explanations that I believe we should part company with them. Solipsism and science, like solipsism and anything else of course, do not go well together. If constructivists argue that no theory is more correct than any other and that “we can never really know anything” then I think they should continue their “game”, as they call it, in their own way, and let those who prefer to work with more rationalist assumptions get on with scientific research.
Postscript on Critical Social Justice
In Part 1, I discussed CSJ in general and mentioned Raciolinguistics in particular. I described the central belief of CSJ, viz.: society is made up of specific identity-based systems of power and privilege that construct knowledge via different forms of discourse. Language is obviously at the heart of CSJ. Pluckrose and Lindsay (2020) say near the end of their book that this central belief is now considered by social justice scholars and activists “to be an objectively true statement about the organizing principle of society”, i.e., it has become reified: what was once a quasi-philosophical theoretical stance has now become an established, unquestioned (and unquestionable!) reality, comprised of identity groups and their associated discourses. Despite the insistence on a relativist epistemology, those committed to CSJ take their beliefs to be the unassailable truth.
The premise that society works through systems of power and privilege maintained in language, and that these create knowledge from the perspectives of the privileged and deny the experiences of the marginalized leads to “Standpoint Theory”, which operates on two assumptions. “One is that people occupying the same social positions, that is, identities—race, gender, sex, sexuality, ability status, and so on—will have the same experiences of dominance and oppression and will, assuming they understand their own experiences correctly, interpret them in the same ways”. The other assumption is that one’s relative position within a social power dynamic dictates what one can and cannot know: “the privileged are blinded by their privilege and the oppressed possess a kind of double sight, in that they understand both the dominant position and the experience of being oppressed by it” (Pluckrose and Lindsay, 2020, 194).
So Standpoint theory says that members of dominant groups experience a world organized by and for dominant groups, while members of oppressed groups experience the world as members of oppressed groups in a world organized by and for dominant groups. “Thus, members of oppressed groups understand the dominant perspective and the perspective of those who are oppressed, while members of dominant groups only understand the dominant perspective. Standpoint theory can be understood by analogy to a kind of color blindness, in which the more privileged a person is, the fewer colors she can see. A straight white male—being triply dominant—might thus see only in shades of gray” (Pluckrose and Lindsay, 2020, 195).
The culmination of all this alarming stuff is the discussion of whiteness and white supremacy. In Part 1, I mentioned Gerald’s Antisocial Language Teaching: English and the Pervasive Pathology of Whiteness, a contribution to the raciolinguistics literature which argues that “the centering of whiteness in ELT renders the industry callous, corrupt and cruel; or, antisocial”and which was shortlisted for the 2023 BAAL book prize. On page 205 of their book, Pluckrose and Lindsay (2020) discuss another contribution to this literature: Robin DiAngelo’s 2018 book White Fragility: Why It Is So Hard To Talk To White People about Race. Below is a small extract from that discussion.
“White Fragility is a state in which even a minimum amount of racial stress becomes intolerable, triggering a range of defensive moves. These moves include the outward display of emotions such as anger, fear, and guilt, and behaviors such as argumentation, silence, and leaving the stress-inducing situation” (DiAngelo, 2018). If a white person expresses negative feelings about being “racially profiled” and held responsible for a racist society, they are assumed to be displaying signs of “fragility”, which is taken as evidence of complicity in racism. DiAngelo states unequivocally that white people are complicit beneficiaries of racism and white supremacy and she is quite explicit in proscribing disagreement. Disagreeing, remaining silent, and going away are all evidence of fragility, and the only way to avoid being fragile is to refrain from showing any negative emotions, to agree with The Truth, and to then actively participate in discovering The Truth, that is, learning how to deconstruct whiteness and white privilege.
Pluckrose and Lindsay (2020, 205 comment “This is quite staggering. DiAngelo, a white woman, contends that all white people are racist and that it is impossible not to be, because of the systems of powerful racist discourses we were born into. She insists that we are complicit by default and are therefore responsible for addressing these systems. Like Applebaum, she argues that it does not matter if individual white people are good people who despise racism and are not aware of having any racist biases: “Being good or bad is not relevant. Racism is a multilayered system embedded in our culture. All of us are socialized into the system of racism. Racism cannot be avoided” (DeAngelo, 2018).
That it should come to this! Not content with throwing out the construction of theories on the basis of a realist epistemology and a methodology based on the testing of hypotheses by appeal to logic, coherent reasoning and appeal to empirical evidence, raciolinguists combine the belief that knowledge is socially constructed with the belief that they are in possession of The Truth. Denying the obvious contradiction involved, they tolerate no dissent, and expect everyone to agree or be “cancelled.” It surely behoves all those who find this approach intellectually incoherent, academically ludicrous and plain scary to speak out against it and to defend that most liberal of liberal values: freedom of speech.
References
Block, D. 1996: Not so fast: some thoughts on theory culling, relativism, accepted findings and the heart and soul of SLA. Applied Linguistics 17,1, 63-83.
Bloor, D. 1976: Science and Social Imagery. Routeledge and Kegan Hall.
Bunge, M. 1996: In Praise of Intolerance to Charlatanism in Academia. In Gross, R, Levitt, N., and Lewis, M. The Flight From Science and Reason. Annals of the New York Academy of Sciences, Vol. 777, 96-116.
Denzin, N.K. and Lincoln, Y.S. (eds.) 1998: Handbook of Qualitative Research. Sage.
Firth, A., and Wagner, J. 1997: On discourse, communication, and (some) fundamental concepts in SLA research. Modem Language Journal, 81,3, 285-300.
Gross, P. and Levitt, N. 1998: Higher Superstition.John Hopkins University Press.
Lincoln, Y. S. and Guba, E.G. 1985: Naturalistic Enquiry. Sage.
Jordan, G. 2004: Theory Construction in SLA. Benjamins.
Lantolf, J. P. 1996: SLA Building: Letting all the flowers bloom. Language Learning 46, 4, 713-749.
Long, M. H. 1997: Construct validity in SLA research: A response to Firth and Wagner. Modem Language Journal 81, 3, 318-323.
Pluckrose, H. and Lindsay, J. (2020) Cynical Theories: How Activist Scholarship Made Everything About Race, Gender, and Identity—and Why This Harms Everybody. Pitchstone Publishing.
Popper, K. R. 1972: Objective Knowledge. Oxford University Press.
Schumann, J. 1978: The pidginization process: A model for SLA. Newbury House.
Searle, J.R. 1993: The World Turned Upside Down. In Madison, G. (ed.) Working Through Derrida. Northwestern University Press.
Shawver, L. 1996: What Postmodernism Can Do for Psychoanalysis: A Guide to the Postmodern Vision. The American Journal of Psychoanalysis, 56(4), pp.371-394.
Twenty years ago, I wrote this, the first paragraph of a book about theories of SLA:
There is a “Science and Culture War” currently raging in academia, and it has spilled over into the field of Second Language Acquisition (SLA). When TESOL Quarterly devoted a special issue to research methods in SLA in 1990, and when Applied Linguistics followed with a special issue on theory construction in SLA in 1993, almost all of the articles in both journals assumed a rationalist approach to theory construction, based on logical reasoning and empirical research. But subsequently, and increasingly in the past few years, a growing number of researchers in SLA have adopted relativist positions of one sort or another, most frequently following the constructivist position of Lincoln (1990) and Guba (1990), or sometimes appealing directly to the work of such post-modernists as Derrida (1973, 1976) and Foucault (1980). Whatever their inspiration, what unites the rebels is their rejection of the methods, assumptions, and authority of the rationalist/empiricist approach to research and theory construction.
Today, it seems that the bad guys have won, and that those who continue to be guided in their academic work by a realist epistemology, a rationalist approach to research, and a humanistic, libertarian approach to education find themselves the targets of increasingly aggressive attacks from “the new puritans” as Doyle (2022) calls them.
Critical Social Justice
The “science and culture War” of the late nineties has morphed into what Pluckrose and Lindsay (2020) refers to as the crusade of the “Critical Social Justice” (CSJ) believers against those who cling to the obsolete values of “Liberal Social Justice”. In their 2012 work, Sensoy and DiAngelo explain CSJ:
A critical approach to social justice refers to specific theoretical perspectives that recognize that society is stratified (i.e., divided and unequal) in significant and far-reaching ways along social group lines that include race, class, gender, sexuality, and ability. Critical social justice recognizes inequality as deeply embedded in the fabric of society (i.e., as structural), and actively seeks to change this.
The definition we apply is rooted in a critical theoretical approach. While this approach refers to a broad range of fields, there are some important shared principles:
All people are individuals, but they are also members of social groups.
These social groups are valued unequally in society.
Social groups that are valued more highly have greater access to the resources of a society.
Social injustice is real, exists today, and results in unequal access to resources between groups of people.
Those who claim to be for social justice must be engaged in self-reflection about their own socialization into these groups (their “positionality”) and must strategically act from that awareness in ways that challenge social injustice.
This action requires a commitment to an ongoing and lifelong process. (p. xviii)
Clearly, the “social groups” referred to are identity groups. CSJ sees society as made up of people divided by their race, sex, class sexuality and ability and then ranked and allocated certain resources depending on their identity. Despite all the empirical evidence which falsifies such a simplistic picture of society, CSJ insists on portraying society as a white supremacist, patriarchal, homophobic, ableist system in which people can plot their “positionality” by their identity and predict consistent results from it. This crude framework is claimed to provide the key to understanding society and to unlocking revolutionary change. As Pluckrose (2020) points out, the assumption that all people are socialised into certain beliefs due to their identity leads to the conclusion that society is the result of people’s immutable characteristics. Critical Theory thus “disempowers the people it seeks to empower”. Pluckrose goes on: “Liberals generally reject this reductionist worldview and seek to overcome racism, sexism and homophobia by consistently objecting to anybody’s worth being evaluated by their race, sex or sexuality and seeking empirical evidence of discrimination and effective ways to overcome it”.
Despite all the weaknesses in their simplistic framework, CSJ claims that society is best seen as made up of undervalued groups who are discriminated against by oppressive power systems who control the way everything is talked about, i.e., discourse. These oppressive power systems permeate everything and are identified as white supremacy, patriarchy, colonialism, heteronormativity, cisnormativity, ableism and fatphobia. Those who don’t recognize these systems and fail to see what’s going on are complicit in the oppressive discourses and systems, while the marginalised are in a much better position to see them and thus more competent to identify and define them. Knowledge is thus tied to identity and to one’s perceived position in society in relation to power – often referred to as “positionality.”
CSJ theorists use this peculiar “critical” methodology to “uncover” the oppressive power systems and set the scene for a revolutionary shift to social justice, which crucially depends on everybody in society accepting the CSJ theorists’ interpretations. Those who reject these interpretations are judged to be stubbornly trying to preserve their own privilege, or suffering from false consciousness, or both.
CSJ theorists and activists adopt a relativist epistemology which denies our ability to obtain objective knowledge. As opposed to scientists and rationalists who adopt a realist epistemology (objective truth exists and can be approximated to through the use of logic, empirical observation and the asymetery between truth and falshood), CSJ adopts a social constructivism view which sees all claims to truth as no more than value-laden constructs of culture. There’s no such thing as objective knowledge, no way we can talk about things and events which corresponds with reality as determined by evidence. Thus, the scientific method has no more legitimacy than any other way of producing “knowledge” – it’s just one cultural approach among many, as corrupted and biased as any other “narrative”. The pursuit of objective knowledge is abandoned in favour of the active pursuit of social justice, and we are caljoled into accepting the CSJ views on no more than their say so. Doyle (2022) gives the example of how CSJ theorists in the field of “Fat Studies” argue that there are no health risks to obesity, claiming that the seemingly irrefutable evidence to the contrary is the result of the bigotry of “the scientific method”. Similarly, as I argued in a recent post about Adrian Holliday’s work, it is asserted – by Holliday – that the scientists’ “positivist ideology” leads them to seeing people from China as being “essentially different”, which results in the further assertion that all scientists are “inherently” racists.
CSJ has nothing to do with critical thinking, i.e., examining an argument or claim in the light of reason and evidence rather than accepting it uncritically. As Baily (2017) makes clear: “Critical pedagogy regards the claims that students make in response to social-justice issues not as propositions to be assessed for their truth value, but as expressions of power that function to re-inscribe and perpetuate social inequalities” (emphasis added). Forget objective knowledge, “critical research is not out to create truth”. The critical research process involves “an active identification of and engagement with power, with the social systems and structures, ideologies and paradigms that uphold the status quo”. It follows that a person engaged in critical social justice practice must be able to recognize that “relations of unequal social power are constantly being enacted at both the micro (individual) and macro (structural) levels.”
Such “logic” is enertgetically rejected by Pluckrose (2022), who questions the CSJ assertion that identity-based power dynamics are constantly in play in every interaction and every system in society. Pluckrose suggests that things are actually “a bit more complicated than this”, and that most people’s lived experience involves seeing others as individuals “rather than as identity-based pawns positioned on a power grid”. What reasoning validates the assertion that identity-based relations of unequal power govern social life? Why, asks Pluckrose, should she “understand” that every time she interacts with a man, he has more power than her and is exercising it against her? Why, every time she interacts with a non-white person, should she “understand” that she has more power than them and that she is exercising that power against them? “Is it that most people fail to “understand” this or is it that most humans who regularly interact with a variety of other humans don’t find it to be true?”
Sensor and DiAngelo urge everybody to “think critically about knowledge; what we know and how we know it”, and go on to warn that disagreeing with the CSJ conception of the world is a symptom of “white fragility”, which occurs whenever white people disagree with and object to the claim that they are inherently racist. Pluckrose (2022) rejoins that fighting for a more socially just society requires acting against Critical Social Justice, not bowing to its dictates. People’s arguments can and should be separated from their identities, “allowing anybody to subscribe to any viewpoint and challenge any viewpoint and not be confined to the one presumptuously deemed to be appropriate for their race, sex or sexuality. It was liberalism that convinced society that women and racial and sexual minorities were individuals with their own minds and voices and in possession of exactly the same moral right to access everything society had to offer (including the full range of ideas). It is this liberal concept of social justice, with its extraordinary record of achievement, that we must defend and further”.
Finally, it’s instructive to look at the short-list competing for the 2023 British Association for Applied Linguistics book prize.
Gender Diversity and Sexuality in English Language Education: New Transnational Voices edited by Darío Luis Banegas and Navan Govender, Bloomsbury. “Informed by critical theories, critical literacy, post-structuralism, queer theory, and indigeneity/(de)coloniality, the critical perspectives in this volume consider gender and sexuality as dimensions of human life and aim to promote sexual, gender, emotional and relational wellbeing together with the construction of cultural horizons and citizenship”.
Mobile-Assisted Language Learning: Concepts, Contexts and Challenges by Glenn Stockwell, Cambridge University Press. This book provides a resource for present and future language teachers, and for graduate students of applied linguistics and TESOL, to understand how mobile devices can best be used for language teaching. How, one wonders, did such a sensible book make the list!
Antisocial Language Teaching: English and the Pervasive Pathology of Whiteness by JPB Gerald, Multilingual Matters. “The centering of whiteness in English Language Teaching (ELT) renders the industry callous, corrupt and cruel; or, antisocial. This book examines major issues with the ideologies and institutions behind the discipline of ELT and diagnoses the industry as in dire need of treatment, with the solution being a full decentering of whiteness.”.
Standards, Stigma, Surveillance by Ian Cushing, Palgrave Macmillan. “This book traces raciolinguistic ideologies in England’s schools, focusing on post- 2010 policy reforms which frame the language practices of low-income, racialised speakers as limited and deficient….. It draws on fields including critical language policy, educational sociolinguistics, genealogy, raciolinguistics and critical language awareness”.
The Inner World of Gatekeeping in Scholarly Publication edited by Pejman Habibie and Anna Kristina Hultgren, Palgrave Macmillan. “A collection of reflective narratives and autoethnographic accounts by a wide range of journal editors and experienced reviewers who shed light on the often mysterious processes of peer review and editing while taking care to locate these within the pressures of neoliberal academia”.
Implicit and Explicit Language Attitudes by Robert M. McKenzie, Andrew McNeill, Routledge. This book “details the findings of a large-scale study, incorporating cutting-edge implicit and self-report instruments adapted from social psychology, investigating the evaluations of over 300 English nationals of the status and social attractiveness of Northern English and Southern English speech in England”.
Cushing, with his “Standards, Stigma, Surveillance” was the lucky winner.
Pluckrose, H. and Lindsay, J. (2020) Cynical Theories: How Activist Scholarship Made Everything About Race, Gender, and Identity—and Why This Harms Everybody. Pitchstone Publishing.
“A study reveals that both intent and accuracy are important in assessing whether something is a lie”.
This is Holliday’s presentation at the 2nd International Symposium on Language Learning and Global Competence (2019).
Holliday says:
Essentialism is to do with ‘Us-Them’ discourse. ‘They’ are essentially different to ‘Us’ because of their culture…… There’s no way we can be the same. There’s something absolutely separate about us and them. …….Culture then becomes a euphemism for race. It’s essentially racist to imagine a group here and a group there who are essentially different to each other. That is the root of racism…….. Any group who is put over there and defined as being different to you, that is the basis of racism.
Holliday attributes this racism to everybody – even he himself in unguarded moments. At minute 18 in his talk he says:
Grand narratives define us and them by fixity and division. We are different to those people, we have to be in order to survive. .. You brand your nation as being different to those people, in a superior or inferior way.
Holliday gives the example of a Chinese student who told him he’d turned down a fantastic job in Mexico “Because Mexico is not as good as Britain”. Holliday continues:
He had a hierarchy in his head. I challenge everybody in this room …. We all position ourselves …There’s no such thing as talking about culture in a neutral way; we just cannot. Everybody is positioning themselves in a hierarchy.
Holliday says:
I remember a long time ago I was in Istanbul interviewing colleagues. We were sitting right on the Bosphorus. And everything that was East was inferior, and everything that was West was superior. This came out, very very clear; very very clear. Even inside Turkey. Yuh.
It’s worth wathching Holliday as he says all this: he’s bonkers.
Discussion
Holliday tells us a story. How does he know all this stuff about what people are thinking?
In particular, what evidence is there that Holliday’s companions made the “essentialist statement” that “‘They’ are essentially different to ‘Us’”? Holliday gives us none, not a shred. We just have to accept that he has somehow correctly read their minds.
Lets suppose we ask a group of scientists, born and raised in France, who all adopt a realist epistemology and carry out quantitative research, to watch a documentary about life in Beijing where the locals are shown working and playing and doing the everyday things they do. Regardless of what they might say, Holliday will insist that the scientists’ “positivist ideology” will make them all think, consciously or not:
“Those people are essentially different to us. There’s no way we can be the same. There’s something absolutely separate about us and them”.
Their view of the Beijing people as “essentially different” means that they’re all racists. In answer to any outraged denials of this charge by the accused scientists, Holliday will say they’re blind to their racism. They can’t help themselves: they can’t escape their cultural influences and the consequences of their “positivist ideology”.
So here’s the question: Do we accept Holliday’s argument that the equation: positivism = essentialism necessarily means that our group of French scientists are racists, or do we call out Holliday as a preposterous bullshitter? Do we allow ourselves to be persuaded for a second by Holliday’s obvious nonsense, or do we push back against it?
To take some more examples,
How does Holliday know when people are imagining “a group here and a group there who are essentially different to each other”? Does he have some special antenna, like a built-in lie detector, or is it a necessary consequences of talking about “large cultures”?
How does he know when people put a group “over there” and define them as being different to us? Where is “over there”?
How does he know that his Mexican student had a hierarchy in his head?
How can he report with such certainty that when he was sitting there with his Turkish colleagues, all of them without exception thought, precisely, that everything to the East of Istanbul was inferior, and everything to the West was superior?
Holliday calls those who adopt a realist epistemology and who value logic and empirical evidence (physicists, chemists, psycholinguists, … all those who call themselves scientists) “positivists”. He equates a “positivist ideology” with racism. Postivists are the bad people. The good people are relativists like him; those who rely on the interpretation of subjective experiences and who reject the scientific, “positivist paradigm”.
Holliday claims that
“the technicalized commodification of methods are implicit in the neoliberal agenda of the university sector”, and that, more generally, “grand narratives of nation, language, and culture are ideologically constructed. They come from politics”.
What does that mean? What ideology constructs the grand naratives” What politics is he talking about? Just for example, is Chomsky’s “grand narrative” that all languages share a deep grammar ideologically motivated? If so, what’s the ideology? Chomsky is a delared anarchist. Is his theory of Universal Grammar an unintended contradiction? Part of the ideology of a neoliberal, capitalist ruling class?
What’s so shocking is how unacademic Holliday is – he seems to think that making things so by definition and then adding a few personal, meaningful anecdotes suffices to drive home necessary truths. Holliday stands on a soap box and preaches. He’s a deluded crusader, out to save us all, and his postmodern armour protects him from silly demands to explain more carefully in plain English what he’s talking about, or to provide reliable evidence for his assertions.
Native speakerism
Holliday’s irrationalism is demonstrated most clearly when he gets on his “Native Speakerism” hobby horse. All talk of native speakers, Holliday insists, is “the voice of the ideology of native speakerism”, where “culturally superior native speakers teach the non-native-speaker-cultural-others how to think and be civilised”. Holliday refuses to review any journal article using the acronyms NS and NNS.
Holliday’s commitment to a qualitative, ethnographic methodology and to a constructivist epistemology happily fuses with his commitment to stamping out racism, any mention of native speakers, and lots more injustices besides. Holliday limits the scope of his descriptions to a single, preferred interpretation which is not just partial, but also ideologically blinkered. To borrow from Widdowson, what Holliday offers is interpretation, not analysis. And very bad interpretation at that.